
Khi kiến thức của bạn về học máy ngày càng tăng, thì số lượng các thuật toán học máy cũng tăng theo. Bài viết này sẽ đề cập đến các thuật toán học máy thường được sử dụng trong cộng đồng khoa học dữ liệu.
Trong bài sẽ có một số thuật toán học máy được giải thích cặn kẽ hơn những thuật toán khác để bài viết ngắn gọn. Sẽ không có quá nhiều hàm lượng toán học trong bài viết để những người không có nhiều kiến thức toán có thể theo. Có thể xem bài viết là một bản tóm tắt ngắn gọn về từng tính năng và một số đặc điểm chính của các thuật toán.
Chúng ta sẽ bắt đầu với một số thuật toán học máy cơ bản và sau đó đi sâu vào một số thuật toán mới như CatBoost, Gradient Boost và XGBoost.
Hồi quy tuyến tính
Hồi quy tuyến tính (Linear Regression) là một trong những thuật toán học máy cơ bản nhất được sử dụng để mô hình hóa mối quan hệ giữa một biến phụ thuộc và một hoặc nhiều biến độc lập. Nói một cách đơn giản hơn, nó liên quan đến việc tìm ‘dòng phù hợp nhất’ (Line of best fit) đại diện cho hai hoặc nhiều biến.
Đường phù hợp nhất được tìm thấy bằng cách giảm thiểu khoảng cách bình phương giữa các điểm và đường phù hợp nhất – điều này được gọi là giảm thiểu tổng các phần dư bình phương (sum of squared residual). Phần dư chỉ đơn giản bằng giá trị dự đoán trừ đi giá trị thực.
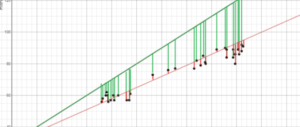
Trong trường hợp nó chưa có ý nghĩa, hãy xem xét hình ảnh trên. So sánh đường màu xanh lá cây phù hợp nhất với đường màu đỏ, hãy chú ý xem các đường thẳng đứng (phần dư) của đường màu xanh lá cây lớn hơn nhiều so với đường màu đỏ như thế nào. Điều này có ý nghĩa vì đường màu xanh lá cây nằm rất xa các điểm nên nó hoàn toàn không phải là sự thể hiện dữ liệu tốt!
Nếu bạn muốn tìm hiểu thêm về toán học đằng sau hồi quy tuyến tính, có thể bắt đầu với lời giải thích của Brilliant.
Hồi quy logistic
Hồi quy logistic (Logistic regression) tương tự như hồi quy tuyến tính nhưng được sử dụng để mô hình hóa xác suất của một số kết quả rời rạc, điển hình là hai. Thoạt nhìn, hồi quy logistic nghe có vẻ phức tạp hơn nhiều so với hồi quy tuyến tính, nhưng thực sự chỉ có một bước bổ sung.
Đầu tiên, bạn tính điểm bằng cách sử dụng một phương trình tương tự như phương trình cho đường phù hợp nhất cho hồi quy tuyến tính.
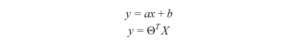
Bước bổ sung là cung cấp điểm số mà bạn đã tính toán trước đó trong hàm sigmoid bên dưới để bạn nhận được xác suất đổi lại. Xác suất này sau đó có thể được chuyển đổi thành đầu ra nhị phân, 1 hoặc 0.
![]()
Để tìm trọng số của phương trình ban đầu để tính điểm, các phương pháp như giảm độ dốc hoặc khả năng xảy ra tối đa được sử dụng. Vì nó nằm ngoài phạm vi của bài viết này nên chúng ta sẽ không đi vào chi tiết, nhưng như vậy cũng đủ giúp bạn hiểu nó hoạt động như thế nào!
K-Nearest Neighbors
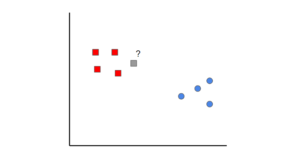
K-nearest neighbors là một ý tưởng đơn giản. Đầu tiên, bạn bắt đầu với dữ liệu đã được phân loại (tức là các điểm dữ liệu màu đỏ và xanh lam). Sau đó, khi bạn thêm một điểm dữ liệu mới, bạn phân loại nó bằng cách xem các điểm được phân loại gần k nhất. Lớp nào nhận được nhiều phiếu bầu nhất sẽ quyết định điểm mới được xếp vào loại nào.
Trong trường hợp này, nếu chúng ta đặt k = 1, chúng ta có thể thấy rằng điểm gần nhất đầu tiên với mẫu màu xám là một điểm dữ liệu màu đỏ. Do đó, điểm sẽ được phân loại là màu đỏ.
Một điều cần lưu ý là nếu giá trị của k được đặt quá thấp, nó có thể bị ngoại lệ. Mặt khác, nếu giá trị của k được đặt quá cao thì nó có thể bỏ qua các lớp chỉ có một vài mẫu.
Naive Bayes
Naive Bayes là một thuật toán phân loại. Điều này có nghĩa là Naive Bayes được sử dụng khi biến đầu ra là rời rạc.
Naive Bayes có vẻ là một thuật toán khó vì nó yêu cầu kiến thức toán học sơ bộ về xác suất có điều kiện và Định lý Bayes, nhưng đó là một khái niệm cực kỳ đơn giản và “ngây thơ”. Chúng ta hãy xem giải thích về thuật toán này bằng một ví dụ:

Giả sử chúng ta có dữ liệu đầu vào về các đặc điểm của thời tiết (triển vọng – outlook, nhiệt độ – temperature, độ ẩm – Humidity, gió – Windy) và liệu bạn có chơi gôn hay không (tức là cột cuối cùng).
Điều mà Naive Bayes làm về cơ bản là so sánh tỷ lệ giữa mỗi biến đầu vào và các danh mục trong biến đầu ra. Điều này có thể được hiển thị trong bảng dưới đây.

Lấy một ví dụ trong bảng trên để bạn hiểu, trong phần nhiệt độ, trời nóng trong hai ngày trong số chín ngày bạn chơi gôn (tức là có).
Theo thuật ngữ toán học, bạn có thể viết giá trị này là xác suất trời nóng khi bạn chơi gôn . Kí hiệu toán học là P (hot | yes). Đây được gọi là xác suất có điều kiện và là điều cần thiết để hiểu phần còn lại của những gì sắp xem sau đây.
Sau khi có được điều này, bạn có thể dự đoán liệu mình có chơi gôn hay không với bất kỳ sự kết hợp nào của các đặc điểm thời tiết.
Hãy tưởng tượng rằng chúng ta có một ngày mới với những đặc điểm sau:
- Triển vọng: nắng
- Nhiệt độ: ôn hòa
- Độ ẩm: bình thường
- Windy: không (false)
Đầu tiên, chúng tôi sẽ tính xác suất bạn sẽ chơi gôn với X, P (yes | X), tiếp theo là xác suất bạn sẽ không chơi gôn với X, P (no | X).
Sử dụng biểu đồ trên, chúng ta có thể nhận được thông tin sau:

Bây giờ chúng ta có thể chỉ cần nhập thông tin này vào công thức sau:

Tương tự, bạn sẽ hoàn thành trình tự các bước tương tự cho P (no | X).
![]()
Vì P (yes | X)> P (no | X), nên bạn có thể dự đoán rằng người này sẽ chơi gôn với điều kiện là trời nắng, nhiệt độ ôn hòa, độ ẩm bình thường và không có gió.
Đây là bản chất của Naive Bayes!
Support Vector Machines
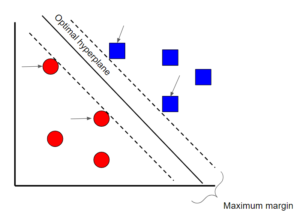
Support Vector Machine là một kỹ thuật phân loại có giám sát có thể khá phức tạp nhưng khá trực quan ở cấp độ cơ bản nhất. Vì lợi ích của bài viết này, chúng ta sẽ mô tả nó ở mức khá cao (high level).
Giả sử rằng có hai lớp dữ liệu. Support Vector Machine sẽ tìm một siêu phẳng (hyperplane) hoặc ranh giới giữa hai lớp dữ liệu để tối đa hóa lề (margin) giữa hai lớp (xem ở trên). Có nhiều mặt phẳng có thể tách hai lớp, nhưng chỉ một mặt phẳng có thể tối đa hóa lề hoặc khoảng cách giữa các lớp.
Nếu bạn muốn tìm hiểu về toán học đằng sau các thuật toán Support Vector Machines, hãy xem loạt bài viết này. (tiếng Anh) hoặc tại đây (tiếng Việt)
Decision Tree
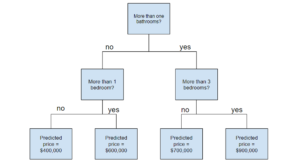
Random Forest
Trước khi hiểu về Random Forest, có một số thuật ngữ mà bạn cần biết:
- Ensemble learning là một phương pháp mà nhiều thuật toán học được sử dụng kết hợp. Mục đích của việc làm như vậy là nó cho phép bạn đạt được hiệu suất dự đoán cao hơn so với việc bạn sử dụng một thuật toán riêng lẻ.
- Bootstrap sampling là một phương pháp lấy mẫu sử dụng lấy mẫu ngẫu nhiên có thay thế. Nghe có vẻ phức tạp nhưng nó THỰC SỰ rất đơn giản – hãy đọc thêm về nó ở đây. (bạn có thể phải dùng VPN để vào link này từ Việt Nam)
- Bagging khi bạn sử dụng tổng hợp các bộ dữ liệu khởi động để đưa ra quyết định – Bạn có thể đọc thêm bài viết cho chủ đề này ở đây.
Bây giờ bạn đã hiểu những thuật ngữ này, hãy đi sâu vào chi tiết.
Random Forest là một kỹ thuật học tập tổng hợp được xây dựng dựa trên các cây quyết định. Random Forest liên quan đến việc tạo nhiều cây quyết định bằng cách sử dụng tập dữ liệu khởi động của dữ liệu gốc và chọn ngẫu nhiên một tập hợp con các biến ở mỗi bước của cây quyết định. Sau đó, mô hình sẽ chọn chế độ (mode) của tất cả các dự đoán của mỗi cây quyết định (bagging). Mục đích của điều này là gì? Bằng cách dựa trên mô hình “đa số thắng”, nó làm giảm nguy cơ mắc lỗi từ một cây riêng lẻ.

Ví dụ, nếu chúng ta tạo ra một cây quyết định, cây thứ ba, nó sẽ dự đoán bằng 0. Nhưng nếu chúng ta dựa vào chế độ (mode) của cả 4 cây quyết định, giá trị dự đoán sẽ là 1. Đây là sức mạnh của các Random Forest
AdaBoost
AdaBoost, hoặc Adaptive Boost, cũng là một thuật toán tổng hợp sử dụng các phương pháp bagging và boosting để phát triển một công cụ dự đoán nâng cao.
AdaBoost tương tự như Random Forest theo nghĩa là các dự đoán được lấy từ nhiều cây quyết định. Tuy nhiên, có ba điểm khác biệt chính làm cho AdaBoost trở nên độc đáo:
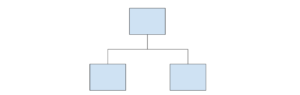
Ví dụ về một gốc cây
- Đầu tiên, AdaBoost tạo ra một khu rừng gốc cây thay vì cây cối. Gốc là cây chỉ được tạo thành từ một nút và hai lá (như hình trên).
- Thứ hai, các gốc cây được tạo ra không có trọng số như nhau trong quyết định cuối cùng (dự đoán cuối cùng). Những gốc cây tạo ra nhiều lỗi hơn sẽ có ít ý nghĩa hơn trong quyết định cuối cùng.
- Cuối cùng, thứ tự thực hiện các gốc cây là rất quan trọng, bởi vì mỗi gốc cây nhằm mục đích giảm thiểu các lỗi mà (các) gốc cây trước đó đã mắc phải.
Về bản chất, AdaBoost có cách tiếp cận lặp lại nhiều hơn theo nghĩa là nó tìm cách cải thiện lặp đi lặp lại từ những sai lầm mà (các) gốc trước đó đã mắc phải.
Nếu bạn muốn tìm hiểu thêm về toán học cơ bản đằng sau AdaBoost, hãy xem bài viết ‘Giải thích toán học về AdaBoost trong 5 phút’
Gradient Boost
Không có gì ngạc nhiên khi Gradient Boost cũng là một thuật toán tổng hợp sử dụng các phương pháp thúc đẩy (boosting) để phát triển một công cụ dự đoán nâng cao. Theo nhiều cách, Gradient Boost tương tự như AdaBoost, nhưng có một số điểm khác biệt chính:
- Không giống như AdaBoost xây dựng các gốc cây, Gradient Boost xây dựng các cây thường có 8–32 lá.
- Gradient Boost xem vấn đề tăng cường (boosting problem) là một vấn đề tối ưu hóa, trong đó nó sử dụng một hàm mất mát (loss function) và cố gắng giảm thiểu lỗi. Đây là lý do tại sao nó được gọi là Gradient boost, vì nó được lấy cảm hứng từ sự giảm dần độ dốc (gradient descent).
- Cuối cùng, cây được sử dụng để dự đoán lượng dư của các mẫu (dự đoán trừ thực tế).
Mặc dù điểm cuối cùng có thể gây nhầm lẫn, nhưng tất cả những gì bạn cần biết là Gradient Boost bắt đầu bằng cách xây dựng một cây để cố gắng phù hợp với dữ liệu và các cây tiếp theo được xây dựng nhằm mục đích giảm phần dư (lỗi). Nó thực hiện điều này bằng cách tập trung vào các khu vực mà những người học hiện có hoạt động kém, tương tự như AdaBoost.
XGBoost
XGBoost là một trong những thuật toán học máy phổ biến và được sử dụng rộng rãi nhất hiện nay vì đơn giản là nó rất mạnh mẽ. Nó tương tự như Gradient Boost nhưng có một vài tính năng bổ sung làm cho nó mạnh hơn nhiều bao gồm…
- Sự thu nhỏ theo tỷ lệ của các nút lá (cắt tỉa) – được sử dụng để cải thiện tính tổng quát của mô hình
- Newton Boosting – cung cấp một tuyến đường trực tiếp đến cực tiểu thay vì giảm độ dốc, làm cho nó nhanh hơn nhiều
- Một tham số ngẫu nhiên bổ sung – giảm mối tương quan giữa các cây, cuối cùng cải thiện sức mạnh của nhóm
- Unique penalization of trees
Tôi thực sự khuyên bạn nên xem video của StatQuest để hiểu chi tiết hơn về cách thuật toán hoạt động.
LightGBM
Nếu bạn nghĩ XGBoost là thuật toán học máy tốt nhất hiện có, hãy nghĩ lại. LightGBM là một loại thuật toán thúc đẩy khác được chứng minh là nhanh hơn và đôi khi chính xác hơn XGBoost.
Điều làm cho LightGBM trở nên khác biệt là nó sử dụng một kỹ thuật độc đáo được gọi là Lấy mẫu một phía dựa trên Gradient (GOSS – Gradient-based One-Side Sampling) để lọc ra các cá thể dữ liệu nhằm tìm ra giá trị phân tách. Điều này khác với XGBoost sử dụng các thuật toán được sắp xếp trước và dựa trên biểu đồ để tìm ra sự phân chia tốt nhất.
Đọc thêm về Light GBM và XGBoost tại đây!
CatBoost
CatBoost là một thuật toán khác dựa trên Gradient Descent có một số khác biệt nhỏ khiến nó trở nên độc đáo:
- CatBoost triển khai cây đối xứng (symmetric trees) giúp giảm thời gian dự đoán và nó cũng có độ sâu của cây nông hơn theo mặc định (sáu)
- CatBoost tận dụng các hoán vị ngẫu nhiên tương tự như cách XGBoost có một tham số ngẫu nhiên
- Tuy nhiên, không giống như XGBoost, CatBoost xử lý các tính năng phân loại một cách thanh lịch hơn, sử dụng các khái niệm như tăng cường theo thứ tự (ordered boosting) và mã hóa phản hồi (response coding)
Nhìn chung, điều làm cho CatBoost trở nên mạnh mẽ là yêu cầu về độ trễ thấp, tức là nó nhanh hơn XGBoost khoảng tám lần.
Nếu bạn muốn đọc chi tiết hơn về CatBoost, hãy xem bài viết này.
Phần kết
Bây giờ bạn có lẽ đã có ý tưởng tốt hơn về tất cả các thuật toán học máy khác nhau.
Đừng nản lòng nếu bạn gặp khó khăn khi hiểu một số thuật toán cuối cùng trong bài, không chỉ phức tạp hơn mà chúng còn tương đối mới. Vì vậy, hãy theo dõi thêm các tài liệu chi tiết để tìm hiểu sâu hơn về các thuật toán này.
Bài của tác giả Terence Shin, Data Scientist | MSc Analytics & MBA student đăng trên towardsdatascience.com
Lưu ý: bạn có thể gặp khó khăn khi truy cập vào các link đến Medium. Hãy thử dùng VPN nếu bạn không thể truy cập theo cách thông thường.







{kind=link}