
Site Reliability Engineering là gì?
Site Reliability Engineering (SRE), hay còn gọi là Kỹ sư quản lý độ tin cậy, là khái niệm ra đời tại Google vào năm 2003, trước khi DevOps bắt đầu thịnh hành. Khi đó nhóm kỹ sư phần mềm được giao nhiệm vụ làm cho các trang web của Google trở nên đáng tin cậy, hiệu quả và luôn sẵn sàng để mở rộng. Các phương pháp mà họ phát triển đã đáp ứng rất tốt nhu cầu của Google đến mức các công ty công nghệ lớn khác, chẳng hạn như Amazon và Netflix, cũng áp dụng và mang lại các kết quả rất tốt.
Google đã mô tả kinh nghiệm và phát hiện của mình trong cuốn “Site Reliability Engineering – How Google Runs Production Systems”. Bạn có thể tải về đọc miễn phí. Cuốn sách giới thiệu các khái niệm như error budgets (tức thời gian tối đa mà hệ thống có thể bị lỗi mà không để lại hậu quả ảnh hưởng đến khách hàng hay hợp đồng), Service Level Objective (SLO – là một thỏa thuận về một số liệu cụ thể như thời gian hoạt động hoặc thời gian phản hồi). Đồng thời cuốn sách cũng mô tả các phương pháp của Google về tự động hóa, xử lý các trường hợp khẩn cấp và sự cố, khắc phục sự cố và giám sát, quản lý rủi ro cũng như xây dựng các hệ thống có thể mở rộng. Cuốn sách cũng đề cập về các khía cạnh như tổ chức nhóm SRE và các nhiệm vụ theo yêu cầu.

Các Kỹ sư Site Reliability làm gì?
Ben Traynor, Phó Giám đốc kỹ thuật tại Google và là người sáng lập Google SRE, đã xác định chính xác bản chất của vai trò SRE trong một cuộc phỏng vấn:
“Về cơ bản, SRE đang thực hiện công việc mà trước đây được thực hiện bởi một đội vận hành (operations). Điều khác biệt là SRE sử dụng các kỹ sư có chuyên môn về phần mềm và những kỹ sư này có khả tự động hóa những hoạt động của con người. Nói chung, nhóm SRE chịu trách nhiệm về tính sẵn sàng, độ trễ, hiệu suất, hiệu quả, quản lý thay đổi, giám sát, ứng phó khẩn cấp và hoạch định công suất. ”
Các Site Reliability Engineer tạo ra cầu nối giữa phát triển và vận hành bằng cách áp dụng tư duy kỹ thuật phần mềm vào các chủ đề quản trị hệ thống. Họ phân chia thời gian giữa việc vận hành và phát triển giúp tăng độ tin cậy và hiệu suất của hệ thống. Google không cho phép các Site Reliability Engineer dành hơn 50% thời gian của họ cho các tác vụ vận hành và coi bất kỳ vi phạm nào đối với quy tắc này là dấu hiệu của một hệ thống không tốt.
Theo Google, mục tiêu cuối cùng của Site Reliability Engineering là tự động hóa để hoàn thành công việc. Một cách quan trọng để làm điều này là xây dựng các công cụ tự phục vụ cho các nhóm người dùng dựa vào dịch vụ họ cần (ví dụ: cung cấp môi trường thử nghiệm tự động, ghi logs, hiển thị báo cáo.. ). Làm như vậy sẽ giảm bớt công việc cần thực hiện cho tất cả các bên, cho phép các nhà phát triển tập trung hoàn toàn vào việc phát triển tính năng và cho phép họ tập trung vào nhiệm vụ tiếp theo để tự động hóa. Các Site Reliability Engineer cộng tác chặt chẽ với các nhóm phát triển sản phẩm để đảm bảo rằng giải pháp đưa ra đáp ứng được các yêu cầu phi chức năng như tính khả dụng, hiệu suất, bảo mật và khả năng bảo trì. Họ cũng làm việc với các kỹ sư phát hành để đảm bảo rằng quy trình phát hành phần mềm là hiệu quả nhất có thể.
Làm sao để trở thành một Site Reliability engineer?
Để trở thành một Site Reliability Engineer, bạn cần có background là kỹ sư phần mềm hoặc kỹ sư hệ thống. Điều quan trọng là bạn có được một nền tảng vững chắc trong cả hai lĩnh vực đó. Đồng thời bạn cần có ý thức về sự cải tiến và tự động hóa. Nếu bạn là một kỹ sư hệ thống và muốn cải tiến kỹ năng lập trình, hoặc bạn là một kỹ sư phần mềm và muốn học cách quản lý những hệ thống có quy mô lớn thì SRE chính là vị trí bạn nên hướng tới.
Tại sao Site Reliability Engineering lại quan trọng?
SRE mang lại rất nhiều lợi ích ý nghĩa:
- Giảm thiểu thời gian để sửa lỗi (time to repair – MTTR) và thời gian trung bình giữa hai lỗi (mean time between failures – MTBF)
- Đẩy nhanh việc cập nhật phần mềm và sửa lỗi.
- Giảm thiểu các rủi ro do con người bằng cách tự động hóa.
- Giảm thiểu sự quá tải của nhân viên.
- Cân bằng sự nỗ lực giữa các developers và đội SRE vì cả hai có cùng mục tiêu
- Nâng cao sự bảo mật và tương thích
- Cân bằng các yêu cầu.
Mức lương của các SRE thế nào?
Trên các site tuyển dụng chuyên ngành IT có thể dễ dàng tìm thấy các vị trí SRE đang tuyển với mức lương trung bình từ 1,000 đến 1,500 USD. Riêng các vị trí lead lương có thể lên đến 3,500 USD tại Việt Nam.

Tại Mỹ, lương trung bình của một SRE là vào khoảng $120K theo Glassdoor.
Khác nhau giữa Site Reliability Engineer và DevOps?
Bạn có thể nghĩ SRE có vẻ giống như DevOps. Nhưng sự thật không phải vậy. DevOps và SRE nên được xem là các quy tắc bổ sung cho nhau. Giữa DevOps và SRE có một số điểm khác nhau cơ bản:
- DevOps thiên về việc tập trung vào việc tăng tốc vòng đời phát triển phần mềm (Soft Ware Development Life Cycle – SDLC) và thắt chặt sự hợp tác giữa đội ngũ vận hành và các kỹ sư phần mềm. DevOps giúp các developer tiếp xúc sâu hơn với các hệ thống đang hoạt động và cho phép các nhóm vận hành dễ dàng thông báo các vấn đề nghiêm trọng cho nhóm phát triển.Trên thực tế, các nhóm SRE là một phần không thể thiếu trong việc xây dựng kiểm thử chủ động, khả năng quan sát, độ tin cậy của dịch vụ và tốc độ để cấu thành một tổ chức lấy DevOps làm trung tâm.
- SRE là một cách để xác định các điểm yếu của hệ thống, kiểm thử các môi trường production và giải quyết các vấn đề trước khi chúng trở nên nghiêm trọng. SRE như là một phần của DevOps, trong đó team tập trung vào việc cải thiện độ tin cậy của các dịch vụ kỹ thuật thông qua việc hợp tác chặc chẽ và chủ động tối ưu hóa các dư thừa cũng như các hoạt động giám sát và cảnh báo.
Bảng dưới đây giúp bạn hình dung sự khác nhau giữa DevOps và SRE theo Google:
|
DevOps |
SRE |
|
Tăng cường sự hợp tác trong tổ chức |
Chia sẻ quyền sở hữa với các developers bằng cách dùng chung các công cụ và kỹ thuật trên toàn bộ hệ thống. |
|
Chấp nhận các thất bại |
Có công thức cho việc cân bằng giữa các sự cố và thất bại trong các lần phát hành mới |
|
Thực hiện sự thay đổi từng bước |
Khuyến khích thay đổi nhanh chóng bằng cách giảm chi phí thất bại (failure cost) . |
|
Tận dụng công cụ và tự động hóa |
Khuyến khích việc tự động hóa các công việc và giảm thiểu các công việc làm bằng tay để tập trung vào những nỗ lực mang lại giá trị lâu dài cho hệ thống. |
|
Đo lường mọi thứ |
Cho rằng các hoạt động (operations) là vấn đề của phầm mềm, và định nghĩa các cách theo quy định để đo lường mức độ sẵn sàng, thời gian hoạt động, thời gian ngừng… |
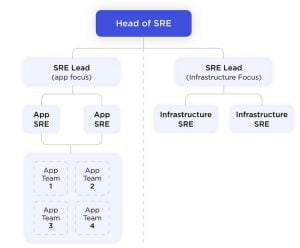
Các vị trí có thể có trong team SRE?
Có nhiều tên gọi khác nhau tùy công ty cho các vị trí trong team SRE trong đó có một số vị trí thông dụng như SRE Team Lead, System Architect, SRE Infrastructure Engineer, Release manager, Monitoring engineer…
Các kỹ năng một SRE cần có là gì?
Trách nhiệm chính của SRE bao gồm theo dõi và phân tích hiệu suất làm việc của các hệ thống đang được vận hành. Tùy thuộc và hệ thống hay dịch vụ mà các chuyên gia SRE dùng các công cụ thích hợp trong công việc của mình. Tuy nhiên, cho dù làm với hệ thống nào và dùng công cụ gì thì một số kỹ năng kỹ thuật và phi kỹ thuật sau đây là yêu cầu cần có đối với mỗi Site Reliability Engineer
Kỹ năng kỹ thuật:
- Nắm vững kiến thức về quản lý phiên bản (version control)
- Chuyên gia về hệ điều hành Linux
- Hiểu về DevOps và biết cách áp dụng.
- Chuyên gia về CI/CD (Continuous Integration and Continuous Delivery)
- Chuyên gia về sử lý vấn đề, xử lý sự cố.
- Có kinh nghiệm về viết code.
- Hiểu về nền tảng phần mềm (software stack)
Kỹ năng mềm:
- Phân tích nghiệp vụ (Business analysis)
- Làm việc nhóm
- Kỹ năng giải quyết vấn đề
- Làm việc dưới áp lực cao
- Kỹ năng giao tiếp, cả về viết lẫn nói
- Kỹ năng diễn giải kỹ thuật cho các đối tượng khác nhau.
Kết luận
Site Reliability Engineering ngày càng quan trọng trong các công ty. Vì vậy việc tuyển dụng các vị trí SRE ngày càng phổ biến không chỉ tại Silicon Valley mà ngay cả ở Việt Nam. Nếu bạn muốn trở thành một SRE hãy bắt đầu chuẩn bị ngay từ bây giờ. Cơ hội sẽ có rất nhiều ở phía trước.
Bạn có biết?
tham gia cộng đồng ITguru trên Linkedin, Facebook và các kênh mạng xã hội khác có thể giúp bạn nhanh chóng tìm được những chủ đề phát triển nghề nghiệp và cập nhật thông tin về việc làm IT mới nhất
Linkedin Page:
Facebook Group:
cơ hội việc làm IT : ITguru.vn






{kind=link}
Chào Ad và những ai quan tâm tới SRE 🙂
Bạn nào quan tâm về SRE thì có thể tham gia event online của bọn mình vào cuối tuần này nhé, chủ đề sẽ về AWS Philosophy trong Reliability Engineering do 1 bạn senior SRE của AWS chia sẻ. Mời bạn vào đây https://gambaru.io/events/te-07-design-for-failure-how-aws-thinks-about-reliability