
Ngày nay bạn có thể nghe các tin tức về machine learning xuất hiện ở khắp mọi nơi. Thực tế, machine learning thật sự có triển vọng. Mặc dù vậy, theo Gartner’s predictions, “Đến năm 2020, 80% dự án AI sẽ vẫn chỉ là mô phỏng, được thực hiện bởi các chuyên gia mà tài năng của họ sẽ không được phát huy trong tổ chức mà họ làm việc”. Transform 2019 of VentureBeat dự đoán rằng 87% dự án AI sẽ không bao giờ đi vào thực tế. Vậy lý do là gì? Tại sao lại có quá nhiều dự án thất bại?
1. Không đủ chuyên môn
Một trong những lý do chính đó là công nghệ này vẫn còn mới đối với hầu hết mọi người. Ngoài ra, các tổ chức vẫn chưa quen với các công cụ phần mềm và phần cứng cần thiết.
Có vẻ như ngày nay, bất kỳ ai đã từng làm việc trong lĩnh vực phân tích dữ liệu hoặc phát triển phần mềm đã thực hiện một số dự án khoa học dữ liệu mẫu đều tự xem mình là nhà khoa học dữ liệu sau khi tham gia một khóa học ngắn hạn trực tuyến.
Thực tế là cần các nhà khoa học dữ liệu có kinh nghiệm để xử lý hầu hết các dự án machine learning và AI, đặc biệt là khi xác định tiêu chí thành công, thực hiện và liên tục giám sát mô hình.
2. Sự khác biệt giữa Khoa học Dữ liệu và Phát triển Phần mềm Truyền thống
Sự khác biệt giữa Khoa học Dữ liệu và Phát triển phần mềm truyền thống là một trong những nguyên nhân chính. Phát triển phần mềm truyền thống có xu hướng dễ dự đoán và đo lường hơn.
Tuy nhiên, Khoa học dữ liệu bao gồm một phần nghiên cứu và một phần kỹ thuật.
Nghiên cứu khoa học dữ liệu tiến lên trước với nhiều lần lặp lại và thử nghiệm. Đôi khi, toàn bộ dự án sẽ phải lặp lại từ giai đoạn triển khai sang giai đoạn lập kế hoạch vì chỉ số được chọn không thúc đẩy hành vi của người dùng.
Dự án dựa trên Agile truyền thống có thể không được mong đợi từ một dự án Khoa học dữ liệu. Điều này sẽ gây ra sự nhầm lẫn trên quy mô lớn cho lãnh đạo, những người đã làm việc với việc phân phối rõ ràng vào cuối mỗi chu kỳ nhiệm vụ cho các dự án phát triển phần mềm thông thường.
Có thể bạn muốn tìm hiểu thêm:
- Lộ trình 7 bước để trở thành chuyên gia Machine Learning
- 10 Câu hỏi phỏng vấn thường gặp trong ngành Machine Learning (Học Máy)
- Doanh nghiệp sẵn sàng chi lương 35 triệu / tháng cho lập trình viên biết AI, Machine Learning, Big Data
3. Khối lượng và chất lượng dữ liệu
Mọi người đều biết rằng tập dữ liệu càng lớn thì khả năng dự đoán từ hệ thống AI càng tốt. Ngoài những tác động trực tiếp của khối lượng lớn hơn, khi kích thước của dữ liệu tăng lên, rất nhiều thách thức mới nảy sinh.
Trong nhiều trường hợp như vậy, bạn sẽ phải hợp nhất dữ liệu từ nhiều nguồn. Khi bạn chuẩn bị bắt tay vào làm việc, bạn sẽ nhận ra rằng dữ liệu không đồng bộ. Điều này sẽ dẫn đến sự nhầm lẫn. Đôi khi bạn sẽ kết thúc việc hợp nhất dữ liệu và nảy sinh vấn đề khi các điểm dữ liệu có cùng tên nhưng ý nghĩa khác nhau.
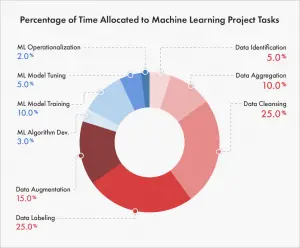
4. Đánh nhãn dữ liệu (Labeling of Data)
Việc không có sẵn dữ liệu được gắn nhãn là một thách thức khác khiến nhiều dự án máy học bị đình trệ. Theo the MIT Sloan Management Review ,
76% lập trình viêcn xử lý thách thức này bằng cách cố gắng tự gắn nhãn và đào tạo chú thích dữ liệu và 63% tiến xa hơn khi cố gắng xây dựng công nghệ tự động hóa ghi nhãn và chú thích của riêng họ.
Điều này có nghĩa là các lập trình viên sẽ tốn khá nhiều thời gian cho việc ghi nhãn. Đây là một thách thức lớn đối trong việc thực hiện dự án AI hiệu quả.
Đây là lý do tại sao nhiều công ty đang thuê các công ty khác làm công việc ghi nhãn. Tuy nhiên, thách thức ở chỗ phải thuê những lập trinh viên có đầy đủ kiến thức về ghi nhãn dữ liệu. Các công ty sẽ phải đầu tư vào việc đào tạo chính thức và tiêu chuẩn hóa nhân viên nếu cần duy trì chất lượng và tính nhất quán trong các tập dữ liệu.
Một lựa chọn khác là phát triển công cụ ghi nhãn dữ liệu của riêng họ nếu dữ liệu được gắn nhãn phức tạp. Tuy nhiên, điều này thường đòi hỏi nhiều chi phí kỹ thuật hơn.
5. Rào cản Silo trong các doanh nghiệp
Dữ liệu là thực thể quan trọng nhất của một dự án học máy. Trong hầu hết các tổ chức, những dữ liệu này sẽ nằm ở những nơi khác nhau với các ràng buộc bảo mật khác nhau và ở các định dạng khác nhau – có cấu trúc, phi cấu trúc, tệp video, tệp âm thanh, văn bản và hình ảnh.
Việc có những dữ liệu này ở những nơi khác nhau với định dạng khác nhau là một thách thức lớn trong việc xử lý. Tuy nhiên, thách thức đó càng tăng gấp bội khi những người có trách nhiệm lại tỏ ra bất hợp tác
6. Thiếu sự hợp tác
Thiếu sự hợp tác giữa các nhóm khác nhau như Nhà khoa học dữ liệu, Kỹ sư dữ liệu, người quản lý dữ liệu, chuyên gia BI, DevOps và lập trình viên, là một thách thức lớn khác. Điều này đặc biệt quan trọng đối với các nhóm trong sơ đồ kỹ thuật của mọi thứ đối với Khoa học dữ liệu vì có rất nhiều khác biệt trong cách họ làm việc và công nghệ họ sử dụng để hoàn thành dự án.
Nhóm kỹ sư sẽ thực hiện mô hình học máy và đưa nó vào thực tiển. Vì vậy, cần có một sự hiểu biết đúng đắn và sự hợp tác chặt chẽ trong quá trình làm việc.
7. Các dự án thiếu tính khả thi về mặt kỹ thuật
Vì chi phí của các dự án machine learning thường rất đắt đỏ, hầu hết các doanh nghiệp có xu hướng nhắm mục tiêu vào một dự án siêu tham vọng và nó sẽ làm thay đổi hoàn toàn công ty hoặc sản phẩm và sẽ mang lại lợi nhuận cao, và sẽ phải đầu tư rất lớn.
Các dự án như vậy sẽ mất nhiều thời gian để hoàn thành. Nó khiến cho các lãnh đạo công ty mất sự tự tin và dừng việc đầu tư.
8. Vấn đề liên kết giữa các nhóm kỹ thuật và kinh doanh
Nhiều khi, các dự án ML được bắt đầu mà không có sự liên kết rõ ràng về kỳ vọng, mục tiêu và tiêu chí thành công của dự án giữa nhóm kinh doanh và khoa học dữ liệu.
Những dự án kiểu này sẽ mãi mãi nằm trong giai đoạn nghiên cứu bởi vì không bao giờ biết liệu chúng có đạt được tiến bộ gì không.
Nhóm khoa học dữ liệu sẽ tập trung chủ yếu vào độ chính xác, trong khi nhóm kinh doanh sẽ quan tâm nhiều hơn đến các chỉ số như lợi ích tài chính hoặc thông tin chi tiết về doanh nghiệp. Cuối cùng, nhóm kinh doanh sẽ không chấp nhận kết quả từ nhóm Khoa học dữ liệu.

9. Thiếu chiến lược về dữ liệu
Theo MIT Sloan Management Review, chỉ 50% doanh nghiệp lớn với hơn 100.000 nhân viên có nhiều khả năng có chiến lược Dữ liệu nhất. Việc phát triển một chiến lược dữ liệu vững chắc trước khi bạn bắt đầu dự án Máy học là rất quan trọng.
Bạn cần hiểu rõ những điều sau như một phần của chiến lược Dữ liệu,
- Tổng dữ liệu bạn có trong công ty
- Bao nhiêu dữ liệu đó thực sự cần thiết cho các dự án?
- Các cá nhân được yêu cầu sẽ có quyền truy cập vào những dữ liệu này như thế nào và những cá nhân đó có thể truy cập chúng dễ dàng như thế nào?
- Chiến lược cụ thể về cách tập hợp tất cả dữ liệu này từ các nguồn khác nhau
- Cách dọn dẹp và chuyển đổi những dữ liệu này.
Hầu hết các công ty bắt đầu mà không có kế hoạch hoặc chưa nghĩ tới chuyện họ không có dữ liệu.
10. Thiếu sự hỗ trợ của lãnh đạo
Thật dễ dàng để nghĩ rằng “bạn chỉ cần ném một số tiền và công nghệ vào vấn đề và kết quả sẽ tự động đến”
Chúng tôi không nhận thấy sự hỗ trợ thích hợp từ ban lãnh đạo để đảm bảo các điều kiện cần thiết để thành công. Đôi khi các nhà lãnh đạo doanh nghiệp không tin tưởng vào các mô hình do các nhà khoa học dữ liệu phát triển.
Điều này có thể là do sự thiếu hiểu biết về AI của lãnh đạo doanh nghiệp và việc nhà khoa học dữ liệu không có khả năng truyền đạt lợi ích kinh doanh của mô hình cho lãnh đạo.
Cuối cùng, các nhà lãnh đạo cần hiểu cách hoạt động của Máy học và AI thực sự có ý nghĩa như thế nào đối với tổ chức. Khi nói đến Machine Learning ứng dụng, phần khó nhất là biết bạn muốn nấu món gì và bạn dự định kiểm tra nó như thế nào trước khi bạn phục vụ nó cho khách hàng của mình. Phần đó thực sự không khó lắm – chỉ cần đừng quên cách làm là được. Đối với phần còn lại, giải quyết các vấn đề kinh doanh với Machine Learning dễ dàng hơn nhiều so với hầu hết mọi người nghĩ. Những nhà bếp lấp lánh đang chờ bạn đến khám phá. Bắt đầu mày mò!
Xem thêm bài viết gốc tại đây !
Bạn có biết?
tham gia cộng đồng ITguru trên Linkedin, Facebook và các kênh mạng xã hội khác có thể giúp bạn nhanh chóng tìm được những chủ đề phát triển nghề nghiệp và cập nhật thông tin về việc làm IT mới nhất
Linkedin Page:
Facebook Group:
cơ hội việc làm IT : ITguru.vn






{kind=link}