
Dữ liệu lớn. Dữ liệu đám mây. Dữ liệu đào tạo trí tuệ nhân tạo. Dữ liệu nhận dạng cá nhân. Dữ liệu ở xung quanh ta, phát triển mỗi ngày và càng quan trọng cuộc sống. Với 2,5 nghìn triệu tỉ byte dữ liệu được tạo ra hàng ngày, các nhà khoa học dữ liệu ngay nay bận rộn hơn bao giờ hết. Khai thác dữ liệu có thể hỗ trợ rất nhiều thứ, từ cá nhân hóa các chiến dịch tiếp thị đến cung cấp thông tin cho ô tô tự lái. Các nhà khoa học dữ liệu (data scientist) chịu trách nhiệm phân tích dữ liệu và sử dụng nó cho các mục đích khác nhau. Tuy nhiên, họ cần dữ liệu có chất lượng tốt để hoàn thành các nhiệm vụ phức tạp, chẳng hạn như dự báo xu hướng cho hoạt động kinh doanh. Và đó là khi chúng ta cần đến các kỹ sư dữ liệu. Kỹ thuật dữ liệu là khoa học thu thập và xác thực thông tin (dữ liệu) để các nhà khoa học dữ liệu có thể sử dụng.
Lương của một kỹ sư dữ liệu ở mức 30-40 triệu cho những người có 3-5 năm kinh kiệm, là một mức khá cao trong ngành. Tuy vậy, việc tuyển dụng các kỹ sư dữ liệu là không hề đơn giản và cung luôn không theo kịp cầu. Với mức lương tốt và nhu cầu cao, có thể xem kỹ thuật dữ liệu là một nghề đáng để theo đuổi. Tuy nhiên, bạn nên tìm hiểu những điều sau trước khi chọn con đường này:
Kỹ thuật dữ liệu là gì?
Chúng ta hãy cùng đi từ bức tranh lớn đến chi tiết. Kỹ thuật dữ liệu (data engineering) là một phần của khoa học dữ liệu, một thuật ngữ rộng bao gồm nhiều lĩnh vực kiến thức liên quan đến làm việc với dữ liệu. Về cốt lõi, khoa học dữ liệu là việc lấy dữ liệu để phân tích nhằm tạo ra những thông tin chi tiết hữu ích và có ý nghĩa. Dữ liệu được sử dụng để cung cấp giá trị cho học máy, phân tích luồng dữ liệu, thông tin kinh doanh hoặc bất kỳ loại phân tích nào khác.
Trong khi khoa học dữ liệu và các nhà khoa học dữ liệu nói riêng quan tâm đến việc khám phá dữ liệu, tìm kiếm thông tin chi tiết về nó và xây dựng các thuật toán học máy, thì kỹ thuật dữ liệu lại quan tâm đến việc làm cho các thuật toán này hoạt động trên cơ sở hạ tầng và tạo đường ống dẫn dữ liệu.
Mục tiêu cuối cùng của kỹ thuật dữ liệu là cung cấp luồng dữ liệu nhất quán, có tổ chức để sử dụng cho các công việc theo hướng dữ liệu, chẳng hạn như:
- Đào tạo mô hình học máy
- Thực hiện phân tích dữ liệu
- Cung cấp dữ liệu cho các ứng dụng
Luồng dữ liệu này có thể đạt được theo nhiều cách và sử dụng các bộ công cụ, các kỹ thuật, kỹ năng cụ khác nhau giữa các nhóm, tổ chức và tùy vào kết quả mong muốn. Tuy nhiên, một mô hình phổ biến là đường ống dữ liệu (data pipeline). Đây là một hệ thống bao gồm các chương trình độc lập thực hiện các hoạt động khác nhau trên dữ liệu được thu thập.
Dưới đây là một sơ đồ đơn giản của một đường ống dữ liệu. Nhiều nguồn dữ liệu đang được đưa vào một hồ dữ liệu (data lake), được chuyển đổi qua nhiều phân đoạn độc lập, sau đó được lưu trữ trong cơ sở dữ liệu thành phẩm (production database). Đường dẫn dữ liệu đơn giản này là cung cấp cho bạn một ý tưởng cơ bản về một kiến trúc mà bạn có thể gặp phải. Tuy nhiên, trong thực tế bạn sẽ thấy các công đoạn phức tạp hơn mà chúng ta khó có thể diễn giải hết chi tiết trong một bài viết.
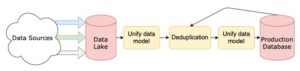
Dữ liệu có thể đến từ bất kỳ nguồn nào:
- Các thiết bị Internet of Things
- Hệ thống ghi nhận thông tin từ xa trên xe cộ
- Nguồn dữ liệu từ các giao dịch thương mại điện tử, dữ liệu bất động sản..
- Hoạt động của người dùng trên một ứng dụng web
- Hoặc bất kỳ công cụ thu thập hoặc đo lường nào khác
Tùy thuộc vào bản chất của các nguồn dữ liệu này mà dữ liệu sẽ được xử lý theo thời gian thực hoặc theo một số nhịp thông thường theo lô. Nếu chúng ta xem đường ống dữ liệu như một loại ứng dụng, thì kỹ thuật dữ liệu cũng giống như ngành kỹ thuật phần mềm dùng để xây dựng nên ứng dụng đó.
Kỹ sư dữ liệu là gì?
Các kỹ sư dữ liệu (data engineer) là những người chịu trách nhiệm về các đường ống mà dữ liệu. Họ chịu trách nhiệm thiết kế, xây dựng, bảo trì, mở rộng và cơ sở hạ tầng hỗ trợ đường ống dẫn dữ liệu. Họ cũng có thể chịu trách nhiệm về dữ liệu đến hoặc thường xuyên hơn là mô hình dữ liệu và cách dữ liệu đó được lưu trữ.
Các nhóm kỹ sư dữ liệu cũng tham gia vào việc xây dựng nền tảng dữ liệu. Với nhiều tổ chức, nếu chỉ có một data pipeline duy nhất chuyển dữ liệu đến cơ sở dữ liệu SQL là không đủ. Các tổ chức lớn có nhiều người sử dụng khác nhau cần các cấp độ truy cập khác nhau vào các loại dữ liệu khác nhau.
Ví dụ: các nhóm trí tuệ nhân tạo (AI) có thể cần những cách để gắn nhãn và phân chia dữ liệu đã được làm sạch. Các chuyên gia Business Intelligent (BI) cần truy cập dữ liệu một cách dễ dàng để tổng hợp dữ liệu và thực hiện hình ảnh hóa dữ liệu. Các nhà khoa học dữ liệu có thể cần quyền truy cập cấp cơ sở dữ liệu để khám phá dữ liệu một cách chính xác.
Nếu bạn đã quen với việc phát triển web, thì bạn có thể thấy cấu trúc này tương tự như mẫu thiết kế Model-View-Controller (MVC). Với MVC, các kỹ sư dữ liệu chịu trách nhiệm về mô hình (model), các nhóm AI hoặc BI làm việc trên các views và các nhóm cộng tác trên controller. Việc xây dựng nền tảng dữ liệu phục vụ tất cả những nhu cầu này đang trở thành ưu tiên trong các tổ chức có các nhóm khác nhau dựa vào quyền truy cập dữ liệu.
Trách nhiệm của kỹ sư dữ liệu
Chúng ta sẽ tìm hiểu về trách nhiệm của Data engineer qua lăng kính về nhu cầu dữ liệu của một số đối tượng sau:
- Các nhà khoa học dữ liệu và AI
- Các nhà phân tích hoặc trí tuệ kinh doanh (business intelligence)
- Các nhóm sản phẩm
Để bất kỳ nhóm nào trong số này có thể hoạt động hiệu quả, một số nhu cầu nhất định phải được đáp ứng. Đặc biệt, dữ liệu phải là:
- Định tuyến đáng tin cậy vào hệ thống rộng lớn
- Được chuẩn hóa thành một mô hình dữ liệu hợp lý
- Làm sạch để lấp đầy những khoảng trống quan trọng
- Tất cả các thành viên có liên quan đều có thể truy cập được
Là một kỹ sư dữ liệu, bạn có trách nhiệm giải quyết các nhu cầu về dữ liệu của người sử dụng. Bạn sẽ cần sử dụng nhiều phương pháp khác nhau để phù hợp với quy trình công việc riêng của từng đối tượng người sử dụng này. Dưới đây là những nhiệm vụ đó:
1) Dòng dữ liệu (data flow)
Để làm bất cứ điều gì với dữ liệu trong hệ thống, trước tiên bạn phải đảm bảo rằng dữ liệu đó có thể đi vào và đi qua hệ thống một cách đáng tin cậy. Đầu vào có thể là hầu hết mọi loại dữ liệu mà bạn có thể tưởng tượng (xem phần kỹ thuật dữ liệu bên trên)
Các kỹ sư dữ liệu chịu trách nhiệm xử lý các dữ liệu đầu vào này, thiết kế một hệ thống có thể lấy dữ liệu này làm đầu vào từ một hoặc nhiều nguồn, biến đổi nó và sau đó lưu trữ cho khách hàng của họ. Các hệ thống này thường được gọi là đường ống ETL, viết tắt của extract, transform và load.
Trách nhiệm của luồng dữ liệu chủ yếu thuộc bước trích xuất (extract). Nhưng trách nhiệm của data engineer không chỉ dừng lại ở việc đưa dữ liệu vào pipeline. Họ phải đảm bảo rằng pipeline đủ mạnh để luôn đối mặt với dữ liệu không mong muốn hoặc không đúng định dạng, các nguồn đang offline và các lỗi nghiêm trọng. Thời gian hoạt động rất quan trọng, đặc biệt khi bạn đang sử dụng dữ liệu trực tiếp hoặc dữ liệu nhạy cảm về thời gian.
Trách nhiệm duy trì luồng dữ liệu của kỹ sư dữ liệu sẽ khá nhất quán cho dù người sử dụng của họ là ai. Tuy nhiên, một số người sử dụng có thể yêu cầu cao hơn những người sử dụng khác, đặc biệt khi họ cần dữ liệu được cập nhật theo thời gian thực.
2) Chuẩn hóa và lập mô hình dữ liệu
Đưa dữ liệu vào một hệ thống là một bước quan trọng. Tuy nhiên, tại một số điểm, dữ liệu cần phải tuân theo một số loại tiêu chuẩn kiến trúc nhất định. Chuẩn hóa dữ liệu (Normalizing data) liên quan đến các tác vụ giúp người dùng dễ truy cập dữ liệu hơn. Điều này bao gồm nhưng không giới hạn ở các bước sau:
- Loại bỏ các bản sao (khử trùng lặp)
- Khắc phục xung đột dữ liệu
- Điều chỉnh dữ liệu thành một mô hình dữ liệu cụ thể
Các quá trình này có thể xảy ra ở các giai đoạn khác nhau. Ví dụ: hãy tưởng tượng bạn làm việc trong một tổ chức lớn với các nhà khoa học dữ liệu và nhóm BI, cả hai đều dựa vào dữ liệu của bạn. Bạn có thể lưu trữ dữ liệu phi cấu trúc trong một data lake để các khoa học dữ liệu sử dụng để phân tích khám phá dữ liệu (exploratory data). Bạn cũng có thể lưu trữ dữ liệu chuẩn hóa trong cơ sở dữ liệu quan hệ hoặc kho dữ liệu (data warehouse) được xây dựng có mục đích để nhóm BI sử dụng trong các báo cáo của mình.
Bạn có thể có nhiều người sử dụng hay ứng dụng sử dụng dữ liệu của bạn. Hình dưới đây cho thấy các giai đoạn khác nhau mà tại đó một số nhóm người sử dụng nhất định có thể truy cập vào dữ liệu:
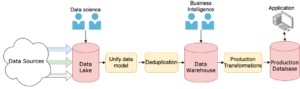
Chuẩn hóa dữ liệu và mô hình hóa dữ liệu thường là một phần của bước chuyển đổi của ETL, nhưng chúng không phải là những bước duy nhất trong danh mục này. Một bước chuyển đổi phổ biến khác là làm sạch dữ liệu.
3) Làm sạch dữ liệu
Làm sạch dữ liệu (data cleaning) đi đôi với chuẩn hóa dữ liệu. Một số người thậm chí còn xem việc chuẩn hóa dữ liệu là một tập hợp con của việc dọn dẹp dữ liệu. Nhưng trong khi quá trình chuẩn hóa dữ liệu chủ yếu tập trung vào việc làm cho dữ liệu khác nhau tuân theo một số mô hình dữ liệu, thì việc làm sạch dữ liệu bao gồm một số hành động giúp dữ liệu đồng nhất và hoàn chỉnh hơn, bao gồm:
- Đổi dữ liệu sang một kiểu duy nhất
- Đảm bảo dữ liệu ngày tháng ở cùng một định dạng
- Điền dữ liệu vào các trường còn thiếu nếu có thể
- Ràng buộc các giá trị của một trường trong một phạm vi được chỉ định
- Xóa dữ liệu bị hỏng hoặc không sử dụng được
Làm sạch dữ liệu có thể phù hợp với các bước mô hình dữ liệu hợp nhất và loại bỏ trùng lặp trong sơ đồ trên. Tuy nhiên, trên thực tế, mỗi bước trong số đó đều rất lớn và có thể bao gồm nhiều giai đoạn và quy trình riêng lẻ khác nhau.
Các hành động cụ thể được thực hiện để làm sạch dữ liệu sẽ phụ thuộc nhiều vào các yếu tố đầu vào, mô hình dữ liệu và kết quả mong muốn. Tuy nhiên, tầm quan trọng của dữ liệu sạch là không đổi:
- Các nhà khoa học dữ liệu cần nó để thực hiện các phân tích chính xác.
- Các kỹ sư học máy cần nó để xây dựng các mô hình tổng quát và chính xác.
- Các đội business intelligence cần nó để cung cấp các báo cáo và dự báo chính xác cho doanh nghiệp.
- Nhóm sản phẩm cần nó để đảm bảo sản phẩm của họ không gặp sự cố hoặc cung cấp thông tin sai lệch cho người dùng.
Trách nhiệm làm sạch dữ liệu thuộc nhiều vai khác nhau và phụ thuộc vào tổ chức và các ưu tiên của tổ chức đó. Là một data engineer, bạn nên cố gắng tự động hóa việc dọn dẹp càng nhiều càng tốt và thường xuyên kiểm tra các dữ liệu đến và dữ liệu được lưu trữ. Người sử dụng và ban lãnh đạo có thể cung cấp thông tin chi tiết về các yếu tố cấu thành dữ liệu sạch cho mục đích của họ.
4) Cung cấp khả năng tiếp cận dữ liệu
Khả năng truy cập dữ liệu không được chú ý nhiều như chuẩn hóa và làm sạch dữ liệu, nhưng đây được cho là một trong những trách nhiệm quan trọng của kỹ thuật dữ liệu lấy khách hàng làm trung tâm.
Khả năng truy cập dữ liệu bao gồm mức độ truy cập dễ dàng và dễ hiểu đến thế nào. Định nghĩa này rất khác nhau tùy thuộc vào người sử dụng:
- Các nhà khoa học dữ liệu có thể chỉ cần dữ liệu có thể truy cập được bằng một số loại ngôn ngữ truy vấn.
- Các nhà phân tích có thể thích dữ liệu được nhóm theo một số chỉ số, có thể truy cập thông qua các truy vấn cơ bản hoặc giao diện báo cáo.
- Các nhóm sản phẩm thường sẽ muốn dữ liệu có thể truy cập được thông qua các truy vấn nhanh chóng và đơn giản, không thay đổi thường xuyên, hướng đến hiệu suất và độ tin cậy của sản phẩm.
Khi các các tổ chức lớn cung cấp cùng một dữ liệu cho các nhóm người dùng khác nhau, các nền tảng nội bộ khác nhau được phát triển để phục vụ cho các đối tượng khác nhau. Một ví dụ điển hình về điều này là dịch vụ đặt xe Uber, đã chia sẻ nhiều chi tiết về nền tảng dữ liệu lớn của mình.
Mối quan hệ và sự khác biệt giữa nhà khoa học dữ liệu và kỹ sư dữ liệu
Trước đây, các công ty nghĩ rằng các Nhà khoa học dữ liệu (data scientist) có thực hiện vai trò của các Kỹ sư dữ liệu. Một số Nhà khoa học dữ liệu cũng tự cho rằng mình có thể làm công việc của Kỹ sư dữ liệu. Tuy nhiên ngày nay, khối lượng và tốc độ dữ liệu đã thúc đẩy Nhà khoa học dữ liệu và Kỹ sư dữ liệu trở thành hai vai trò riêng biệt và khác biệt mặc dù có một số chồng chéo.

Các công ty giờ đây đều công nhận rằng họ cần cả Nhà khoa học dữ liệu và Kỹ sư dữ liệu trong một nhóm phân tích nâng cao. Khá khó để thực hiện bất kỳ tác vụ khoa học dữ liệu có ý nghĩa nào mà không có data engineer hỗ trợ. Cần có sự hợp tác thường xuyên giữa Kỹ sư dữ liệu và Nhà khoa học dữ liệu cho dù các kỹ năng ưu tiên và kiến thức về các công cụ của họ là khác nhau.
Các nhà khoa học dữ liệu tập trung vào phân tích nâng cao dữ liệu được tạo và lưu trữ trong cơ sở dữ liệu. Kỹ sư dữ liệu thiết kế, quản lý và tối ưu hóa luồng dữ liệu với các cơ sở dữ liệu trong tổ chức. Vì vậy, các Nhà khoa học dữ liệu sẽ cần kỹ năng về toán học và thống kê, R, thuật toán và kỹ thuật học máy. Kỹ sư dữ liệu sẽ thông thạo hơn về SQL, MySQL và NoSQL, các kiến trúc và công nghệ đám mây cũng như các framework như agile và scrum. Cả hai nhóm này có thể sẽ biết Python, các kỹ thuật trực quan hóa dữ và các ngôn ngữ lập trình khác.
Các kỹ năng cần có của kỹ sư dữ liệu
Kỹ sư dữ liệu cần có nhiều kỹ năng liên quan đến ngôn ngữ lập trình, cơ sở dữ liệu và hệ điều hành. Điều quan trọng của một data engineer là không cần biết tất cả mọi thứ, nhưng nhưng cần biết “đủ”. Dưới đây là 10 lĩnh vực kiến thức một kỹ sư dữ liệu cần có:
1) Ngôn ngữ lập trình
Kỹ sư dữ liệu cần có kiến thức chuyên môn tối thiểu về các ngôn ngữ lập trình dùng trong khoa học dữ liệu:
- SQL: Để thiết lập, truy vấn và quản lý hệ thống cơ sở dữ liệu. SQL không phải là ngôn ngữ “kỹ thuật dữ liệu”, nhưng các kỹ sư dữ liệu sẽ cần phải làm việc với cơ sở dữ liệu SQL thường xuyên.
- Python: Để tạo các đường ống dẫn dữ liệu, hãy viết các tập lệnh ETL và để thiết lập các mô hình thống kê và thực hiện phân tích. Giống như R, đây là một ngôn ngữ quan trọng cho khoa học dữ liệu và kỹ thuật dữ liệu. Nó đặc biệt quan trọng đối với các ứng dụng ETL, phân tích dữ liệu và học máy.
- R: Để phân tích dữ liệu và thiết lập các mô hình thống kê, trang tổng quan và hiển thị trực quan. Giống như Python, đây là một ngôn ngữ quan trọng cho khoa học dữ liệu và kỹ thuật dữ liệu. Cũng rất hữu ích cho các ứng dụng phân tích dữ liệu và học máy.
Kiến thức về các ngôn ngữ kịch bản này cho phép các data engineer khắc phục sự cố và cải thiện hệ thống cơ sở dữ liệu. Nó cũng cho phép họ tối ưu hóa các công cụ thông tin chi tiết về doanh nghiệp và hệ thống máy học mà họ đang làm việc. Các data engineer cũng có thể được hưởng lợi từ việc quen thuộc với Java, NoSQL, Julia, Scala, MATLAB và TensorFlow.
2) Hệ thống cơ sở dữ liệu quan hệ và phi quan hệ
Kỹ sư dữ liệu cần biết cách làm việc với nhiều nền tảng dữ liệu khác nhau. Các hệ thống cơ sở dữ liệu quan hệ dựa trên SQL (RDBMS) như MySQL, PostgreSQL, Microsoft SQL Server. Các kỹ sư dữ liệu cũng nên phát triển các kỹ năng làm việc với cơ sở dữ liệu NoSQL như MongoDB, Cassandra, Couchbase …
3) Giải pháp ETL
Các kỹ sư dữ liệu nên cảm thấy thoải mái khi sử dụng các hệ thống ETL. Các công cụ ETL hỗ trợ trích xuất, chuyển đổi và tải dữ liệu vào kho dữ liệu. Họ cũng nên hiểu cách sử dụng các giải pháp ETL để hỗ trợ việc chuyển đổi và di chuyển dữ liệu từ hệ thống lưu trữ hoặc ứng dụng này sang hệ thống lưu trữ hoặc ứng dụng khác.
4) Data Warehouses
Sau khi trích xuất thông tin từ các hệ thống khác nhau, các data engineer có thể cần chuẩn bị thông tin để tích hợp nó với hệ data warehouses. Tích hợp dữ liệu là rất quan trọng nếu họ muốn truy vấn nó để có thông tin chi tiết. Kho dữ liệu dựa trên đám mây tạo thành xương sống của hầu hết các hệ thống dữ liệu business intelligence. Các kỹ sư dữ liệu nên hiểu cách thiết lập kho dữ liệu dựa trên đám mây. Họ phải thành thạo trong việc kết nối nhiều loại dữ liệu với nó và tối ưu hóa các kết nối đó để có tốc độ và hiệu quả.
5) Data lake
Data warehouse chỉ có thể hoạt động với thông tin có cấu trúc, chẳng hạn như thông tin trong cơ sở dữ liệu quan hệ. Hệ thống cơ sở dữ liệu quan hệ lưu trữ dữ liệu trong các cột và hàng được xác định rõ ràng. Trong khi đó, các data lake có thể hoạt động với bất kỳ loại dữ liệu nào. Điều này bao gồm thông tin phi cấu trúc, chẳng hạn như dữ liệu truyền trực tuyến. Các giải pháp BI có thể kết nối với các data warehouses để thu được những thông tin chi tiết có giá trị. Vì lý do này, nhiều công ty đang kết hợp các data lake vào cơ sở hạ tầng thông tin của họ.
Để áp dụng các thuật toán học máy vào dữ liệu phi cấu trúc, điều quan trọng là phải biết cách tích hợp dữ liệu và kết nối nó với nền tảng business intelligence.
6) Kết nối
Các kỹ sư dữ liệu phát triển các data pipeline thiết yếu kết nối các hệ thống thông tin khác nhau. Do đó, các data engineer nên có hiểu biết về các đường ống dẫn dữ liệu. Kỹ sư dữ liệu nên biết cách giúp các bộ phận khác nhau của mạng thông tin giao tiếp với nhau. Ví dụ: có thể làm việc với REST, SOAP, FTP, HTTP và ODBC — và hiểu các chiến lược để kết nối một hệ thống thông tin hoặc ứng dụng này với một hệ thống thông tin hoặc ứng dụng khác một cách hiệu quả nhất có thể.
7) Nhập dữ liệu
Nhập dữ liệu (data ingestion) đề cập đến việc trích xuất dữ liệu từ các nguồn khác nhau. Trong quá trình trích xuất, kỹ sư dữ liệu cần phải chú ý đến các định dạng và giao thức áp dụng cho tình huống — tất cả trong khi trích xuất dữ liệu một cách nhanh chóng và liền mạch.
8) Cấu hình hệ thống BI
Sau khi lưu trữ dữ liệu, các nhà khoa học dữ liệu thiết lập các kết nối quan trọng giữa các nguồn thông tin. Những nguồn này có thể là kho dữ liệu, siêu thị dữ liệu, data lake và ứng dụng. Việc thiết lập kết nối giữa các nguồn có thể liên quan đến việc hiển thị dữ liệu của công ty với các thuật toán máy học nâng cao cho hoạt động business intelligence. Các kỹ sư dữ liệu phải hiểu cách thức hoạt động của quy trình này để hỗ trợ các nhà khoa học dữ liệu trong công việc của họ.
9) Xây dựng Dashboard
Nhiều nền tảng trí tuệ kinh doanh và máy học cho phép người dùng phát triển các bảng điều khiển tương tác, đẹp mắt. Các trang tổng quan này hiển thị kết quả của các truy vấn, dự báo AI và hơn thế nữa. Thông thường, việc tạo trang tổng quan là trách nhiệm của các nhà khoa học dữ liệu. Tuy nhiên, các data engineer có thể hỗ trợ các nhà khoa học dữ liệu trong quá trình này. Nhiều nền tảng BI và giải pháp RDBMS cho phép người dùng tạo bảng điều khiển thông qua giao diện kéo và thả. Tuy nhiên, kiến thức về SQL, R và Python có thể hữu ích. Nó cho phép kỹ sư dữ liệu hỗ trợ nhà khoa học dữ liệu thiết lập trang tổng quan phù hợp với nhu cầu của họ.
10) Học máy
Về cơ bản, học máy là lĩnh vực của các nhà khoa học dữ liệu. Tuy nhiên, vì kỹ sư dữ liệu là những người xây dựng cơ sở hạ tầng dữ liệu hỗ trợ hệ thống máy học, nên điều quan trọng là họ cảm thấy thoải mái với thống kê và mô hình dữ liệu. Hơn nữa, không phải tất cả các tổ chức sẽ có một nhà khoa học dữ liệu. Do đó, bạn nên hiểu cách thiết lập bảng điều khiển BI, triển khai thuật toán máy học và trích xuất thông tin chi tiết chuyên sâu một cách độc lập.
Làm thế nào để trở thành một kỹ sư dữ liệu?
Không có con đường rõ ràng để trở thành một data engineer. Mặc dù hầu hết các data engineer học bằng cách phát triển các kỹ năng của họ trong công việc, bạn có thể có được nhiều kỹ năng cần thiết thông qua quá trình tự học, giáo dục đại học và học tập dựa trên dự án.
1) Bằng đại học
Không cần phải có bằng đại học để trở thành một data engineer. Tuy nhiên, có được loại bằng cấp phù hợp sẽ hữu ích. Đối với một kỹ sư dữ liệu, bằng cử nhân về kỹ thuật, khoa học máy tính, vật lý hoặc toán học ứng dụng là đủ. Tuy nhiên, bạn có thể lấy bằng thạc sĩ về kỹ thuật máy tính hoặc khoa học máy tính. Nó sẽ giúp bạn cạnh tranh với những ứng viên khác khi xin việc — ngay cả khi bạn chưa có kinh nghiệm làm việc trước đó với vai trò là một kỹ sư dữ liệu.
2) Học trực tuyến
Một số kỹ sư dữ liệu có thể tự học qua các chương trình học trực tuyến. Tin hay không tùy bạn, có lẽ bạn có thể tìm hiểu hầu hết những điều bạn cần biết bằng cách xem video trên YouTube. Ví dụ bài viết này liệt kê một số video YouTube giúp đặt nền tảng để trở thành kỹ sư dữ liệu.
Dưới đây là một số khóa học trực tuyến miễn phí để tìm hiểu những kiến thức cơ bản về kỹ thuật dữ liệu:
- Hướng dẫn dành cho người mới bắt đầu về kỹ thuật dữ liệu (Phần 1), (Phần 2), (Phần 3): Các bài viết này trên Phương tiện sẽ giúp bạn hiểu những kiến thức cơ bản về kỹ thuật dữ liệu và khoa học dữ liệu. Họ cũng sẽ giúp bạn hiểu mô hình dữ liệu, phân vùng dữ liệu và các chiến lược để trích xuất, chuyển đổi và tải (ETL) dữ liệu. Nếu bạn muốn đi sâu hơn bài viết này, thì hướng dẫn này là nơi tốt nhất để bắt đầu.(lưu ý bạn cần membership để đọc và có thể cần VPN để đọc các bài viết trên Medium từ Việt Nam)
- Kỹ thuật dữ liệu Nanodegree của Udacity: Udacity là công ty cung cấp chương trình giáo dục trực tuyến, miễn phí, chất lượng cao về toán học và công nghệ. Họ có toàn bộ chuyên ngành dành riêng cho việc giảng dạy kỹ thuật dữ liệu.
3) Học tập dựa trên dự án
Việc tìm kiếm động lực để hoàn thành các khóa học kỹ thuật dữ liệu trực tuyến có thể khó khăn. Nhiều data engineer sẽ bỏ cuộc trước khi chân ướt chân ráo bước vào nghề. Nếu điều đó xảy ra với bạn, hãy xem xét phương pháp học tập dựa trên dự án. Chọn một dự án mà bạn cảm thấy thú vị. Học các kỹ năng mà bạn cần để hoàn thành dự án. Học tập dựa trên dự án có thể là cách học kỹ thuật dữ liệu thực tế và thú vị hơn.
Để tiếp thêm nhiều năng lượng cho phương pháp học tập dựa trên dự án, hãy cân nhắc viết về công việc và nghiên cứu của bạn. Viết blog về chủ đề kỹ thuật dữ liệu. Bạn cũng có thể đăng các dự án cá nhân của mình lên Github và đóng góp cho các dự án đang mở trên Github. Những việc này sẽ nâng cao tín nhiệm của bạn đối với các nhà tuyển dụng tiềm năng.
4) Chứng chỉ nghề nghiệp
Có nhiều khóa học cấp chứng chỉ chuyên nghiệp về khoa học dữ liệu và kỹ thuật dữ liệu. Dưới đây là danh sách các khóa học chứng chỉ phổ biến nhất về kỹ thuật dữ liệu:
- Chứng chỉ của nhà cung cấp: Oracle, Microsoft, IBM, Cloudera và nhiều công ty công nghệ khoa học dữ liệu khác cung cấp khóa đào tạo về các chứng chỉ có giá trị trong sản phẩm của họ.
- Certified Data Management Professional (CDMP):: Hiệp hội Quản lý Dữ liệu Quốc tế (DAMA) đã phát triển chương trình CDMP như một chứng chỉ để trở thành một chuyên gia cơ sở dữ liệu chung.
- Cloudera Certified Professional (CCP) Data Engineer: Cloudera CCP là chứng chỉ dành cho các kỹ sư dữ liệu chuyên nghiệp. Nó bao gồm các chủ đề như chuyển đổi dữ liệu, sắp xếp và lưu trữ thông tin, nhập dữ liệu, v.v.
- Google Cloud Certified Professional Data Engineer: Ứng viên có thể nhận được chứng chỉ kỹ sư dữ liệu Google Cloud sau khi vượt qua thành công bài kiểm tra kéo dài hai giờ.
Các nguồn thông tin tham khảo
1/ What is Data Engineer: Role Description, Responsibilities, Skills, and Background
2/What Is Data Engineering and Is It Right for You?
3/Data Engineering: What is a Data Engineer and How Do I Become One?
Bạn có biết?
tham gia cộng đồng ITguru trên Linkedin, Facebook và các kênh mạng xã hội khác có thể giúp bạn nhanh chóng tìm được những chủ đề phát triển nghề nghiệp và cập nhật thông tin về việc làm IT mới nhất
Linkedin Page:
Facebook Group:
cơ hội việc làm IT : ITguru.vn







{kind=link}