
Theo một nghiên cứu của trang web tuyển dụng The Ladder, các nhà tuyển dụng sẽ chỉ cần 7.4 giây để chọn các CV có ấn tượng đối với họ. Điều này không chỉ đúng cho các ngành mà ngay cả đối với lĩnh vực Data Science. Trong bài viết của Elad Cohen, VP Data Science tại Riskified, sẽ chỉ cho bạn những điểm đã giúp anh sàng lọc các CV data science xin việc nhanh và chính xác.
Mặc dù theo Elad, không thể đảm bảo rằng những người khác sử dụng chung các cách này cho các vị trí công việc khác nhau sẽ đúng, nhưng chỉ cần bạn chú ý đến những điểm quan trọng này sẽ giúp bạn chinh phục được nhà tuyển dụng ngay từ vòng đầu tiên.
Dưới đây là 7 kinh nghiệm được sử dụng để sàng lọc CV dành cho vị trí lập trình viên Data Science mới nhất năm 2020:
1. Kinh nghiệm làm việc trước đây ở vị trí Data Scientist
Tôi sẽ nhanh chóng xem qua CV của bạn để xem các vị trí trước đây của bạn và xem vị trí nào được đánh dấu là ‘Data Scientist’. Có một số thuật ngữ liền kề khác (tùy thuộc vào vai trò mà tôi đang tuyển dụng), chẳng hạn như “Machine Learning Engineer”, “Research Scientist” hoặc “Algorithm Engineer”. Tôi không đưa vị trí ‘Data Analyst’ vào nhóm này vì công việc hàng ngày của họ khác với công việc của lập trình viên Data Scientist và chức danh Data Analyst là một thuật ngữ cực kỳ rộng.
Nếu công việc hiện tại của bạn có liên quan tới lĩnh vực khoa học dữ liệu và bạn có một số mô tả công việc sáng tạo khác, bạn có thể tìm kiếm các công việc về lập trình viên Data Scientist.
Ngoài ra, nếu bạn đã từng bootcamp về khoa học dữ liệu hoặc là thạc sĩ fulltime trong lĩnh vực này, thì đây có thể sẽ được coi là bước khởi đầu cho sự nghiệp lập trình viên khoa học dữ liệu của bạn.
2. Thành tích kinh doanh đạt được
Tôi muốn đọc những gì bạn đã làm (khía cạnh kỹ thuật) và kết quả kinh doanh. Rất hiếm các lập trình viên data scientists hiểu biết về kỹ thuật có thể nói chuyện về kinh doanh. Nếu bạn có thể chia sẻ các KPI kinh doanh mà công việc của bạn đã ảnh hưởng, điều này rất tuyệt vời. Ví dụ: cho biết mức độ cải thiện AUC thông qua mô hình của bạn, nhưng việc giải quyết tỷ lệ chuyển đổi tăng do cải tiến mô hình có nghĩa là bạn sẽ đạt được điều đó – tác động kinh doanh mới là điều thực sự quan trọng vào cuối ngày. So sánh các lựa chọn thay thế sau đây mô tả cùng một công việc với điểm nhấn khác (kỹ thuật và kinh doanh):
- a. Mô hình lãi suất mặc định của khoản vay ngân hàng – AUC của mô hình được cải thiện là Precision-Recall từ 0,94 lên 0,96.
- b. Mô hình lãi suất mặc định khoản vay ngân hàng – tăng doanh thu hàng năm của đơn vị kinh doanh lên 3% (500 nghìn đô la hàng năm) trong khi duy trì tỷ lệ mặc định không đổi.
3. Giáo dục
Trình độ học vấn chính thức của bạn là gì và trong lĩnh vực nào. Nó có phải là một trường học uy tín và chất lượng? Đối với điểm tốt nghiệp gần đây hơn, tôi cũng sẽ xem xét điểm trung bình của họ và liệu họ có nhận được bất kỳ giải thưởng hoặc danh hiệu xuất sắc nào hay không. Vì Khoa học dữ liệu là một lĩnh vực rộng mở mà không có bất kỳ bài kiểm tra tiêu chuẩn nào hoặc kiến thức bắt buộc, mọi người có thể tham gia lĩnh vực này bằng nhiều phương pháp khác nhau.
Có thể bạn muốn tìm hiểu thêm:
- Chuẩn bị tốt cho cuộc phỏng vấn trong ngành khoa học dữ liệu (Data Science)
- 12 kỹ năng cần nắm vững để làm trong ngành khoa học dữ liệu
- Lộ trình 7 bước để trở thành chuyên gia Machine Learningi
4. Bố cục CV Data Science rõ ràng và gọn gàng
Tôi đã thấy một số CV Data Science đẹp (tôi đã lưu một vài CV để làm tư liệu sau này) nhưng tôi cũng nhận được các files văn bản (.txt) không có định dạng. Tự tạo một CV Science hoàn chỉnh cho bản thân có thể là một công việc khó khăn và nếu bạn đã chọn khoa học dữ liệu làm mục tiêu nghề nghiệp của mình thì rất có thể bạn không thích tạo ra những thiết kế thẩm mỹ vào thời gian rảnh rỗi. Không cần quá màu mè, bạn chỉ cần tìm kiếm một mẫu CV đẹp cho phép bạn thực hiện mọi thứ một cách đơn giản. Sử dụng diện tích trang giấy hợp lý – sẽ hữu ích khi tách trang và đánh dấu các phần cụ thể không nằm trong trải nghiệm làm việc / giáo dục theo trình tự thời gian. Điều này có thể bao gồm hệ thống công nghệ mà bạn đã quen thuộc, danh sách các dự án tự làm, liên kết đến github hoặc blog của bạn và những thứ khác. Một vài biểu tượng đơn giản cũng có thể giúp nhấn mạnh phần tiêu đề.
Nhiều ứng viên sử dụng 1–5 sao hoặc biểu đồ thanh bên cạnh mỗi ngôn ngữ / công cụ mà họ quen thuộc. Cá nhân tôi không phải là một người yêu thích phương pháp này vì một số lý do:
- Điều đó cực kỳ chủ quan – ‘5 sao’ của bạn có giống với ‘2 sao’ của người khác không?
- Kết hợp languages với tools và trong trường hợp xấu nhất là các kỹ năng mềm – nói rằng ‘4,5 sao’ của bạn ở vị trí Lãnh đạo nghe có vẻ không phù hợp. Là một người tin tưởng vào tâm lý phát triển, việc đưa ra tối đa một kỹ năng (đặc biệt là kỹ năng mềm khó định lượng hơn và khó thành thạo hơn) cho thấy bạn là người quá tự tin vào bản thân.
- Tôi cũng đã thấy cách tiếp cận này bị lạm dụng nhiều hơn nữa khi thực hiện các biện pháp chủ quan và thay bằng biểu đồ hình tròn (30% python, 10% teamwork, v.v.). Mặc dù đây có lẽ được cho là một cách sáng tạo để nổi bật, nhưng nó cho thấy sự thiếu hiểu biết cơ bản đằng sau các khái niệm về các biểu đồ khác nhau.
Dưới đây là hai ví dụ về CV Data Science mà tôi thấy hấp dẫn về mặt hình ảnh, với các chi tiết được làm mờ để ẩn danh.

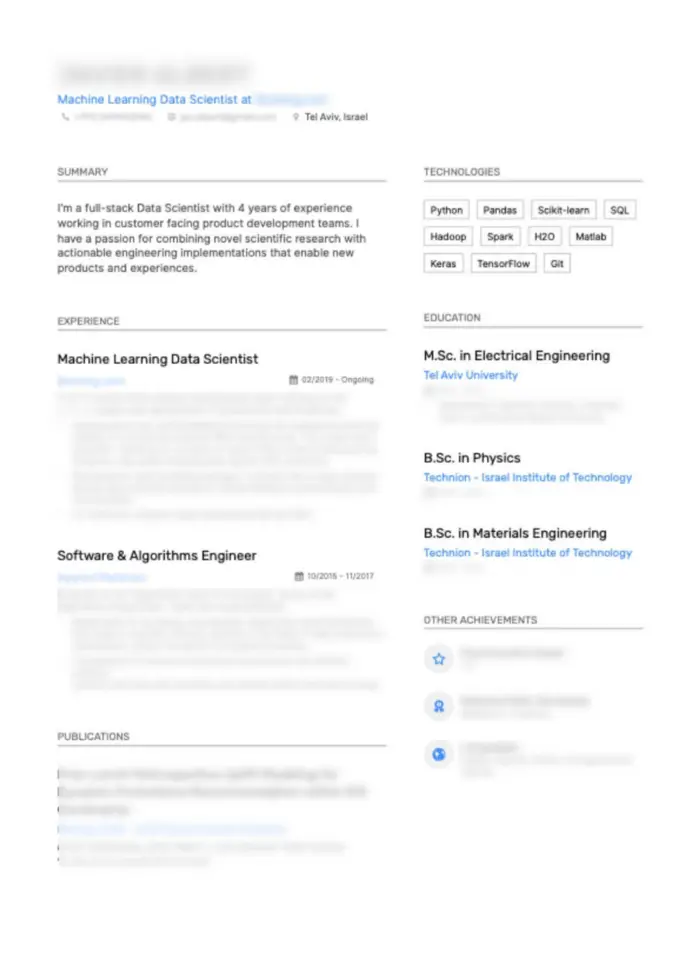
Trên là 2 ví dụ về CV mẫu dành cho lập trình viên Data Science rất hấp dẫn trực quan, phần chi tiết đã bị làm mờ. Lưu ý sự phân chia theo chiều dọc được sử dụng trong cả hai ví dụ để phân biệt kinh nghiệm, kỹ năng, thành tích và giáo dục. Ở cả 2 CV đều có phần tóm tắt ngắn giúp mô tả lý lịch và mong muốn của họ.
5. Machine Learning
Có hai loại tôi tìm kiếm trong một CV cho vị trí Data Science:
- Loại thuật toán – structured/classic ML so với Deep Learning. Một số ứng viên chỉ làm việc với Deep Learning, bao gồm cả dữ liệu có cấu trúc có thể phù hợp hơn với mô hình tree-based models. Mặc dù không có vấn đề gì khi trở thành chuyên gia về DL, nhưng việc giới hạn bộ công cụ có thể hạn chế giải pháp của bạn. Như Maslow đã nói: “Nếu công cụ duy nhất bạn có là một cái búa, bạn có xu hướng coi mọi vấn đề như một cái đinh”. Tại Riskified, chúng tôi xử lý dữ liệu có cấu trúc, domain-driven, được thiết kế theo tính năng, được xử lý tốt nhất với nhiều dạng boosting trees đẩy khác nhau.
- Lĩnh vực ML – điều này thường liên quan trong hai lĩnh vực đòi hỏi nhiều kiến thức chuyên môn – tầm nhìn máy tính và NLP. Các chuyên gia trong các lĩnh vực này đang có nhu cầu và trong nhiều trường hợp, toàn bộ sự nghiệp của họ sẽ được tập trung vào các lĩnh vực này. Vì vậy, nếu hầu hết kinh nghiệm của bạn là về NLP và bạn đang ứng tuyển vào một vị trí không đúng chuyên môn, hãy cố gắng nhấn mạnh các vị trí / dự án mà bạn đang làm có liên quan tới cấu trúc dữ liệu để tạo ấn tượng với nhà tuyển dụng.
6. Tech Stack
Thường có thể được chia thành các ngôn ngữ, các gói cụ thể (scikit learning, pandas, dplyr, v.v.), cloud và các dịch vụ (AWS, Azure, GCP) hoặc các công cụ khác. Một số ứng viên kết hợp điều này với các thuật toán hoặc kiến trúc mà họ quen thuộc (RNN, XGBoost, K-NN). Lưu ý dựa theo kinh nghiệm của tôi, tôi thích các Tech Stack xoay quanh các công nghệ và công cụ; khi một thuật toán cụ thể được đề cập, điều đó khiến tôi tự hỏi liệu kiến thức ML lý thuyết của ứng viên có bị giới hạn trong các thuật toán cụ thể đó hay không.
Ở đây, tôi đang tìm kiếm mức độ liên quan về tech stack – tech stack có từ vài năm trở lại đây (một dấu hiệu tích cực cho thấy ứng viên đang thực hành và học hỏi các kỹ năng mới).
7. Dự án
Bạn có thể chia sẻ điều gì đó trên GitHub không? Bất kỳ cuộc thi nào hoặc dự án phụ nào của Kaggle đều có thể rất hữu ích và cho phép xem code ngắn gọn, các loại preprocessing, tính năng, EDA, lựa chọn thuật toán và vô số vấn đề khác cần được giải quyết trong một dự án ngoài đời thực. Thêm liên kết đến tài khoản GitHub và Kaggle của bạn để nhà tuyển dụng tìm hiểu sâu hơn về code của bạn. Nếu bạn chưa có nhiều kinh nghiệm, rất có thể bạn sẽ được hỏi về một hoặc nhiều dự án trong số này. Trong một số cuộc phỏng vấn mà tôi đã thực hiện, ứng viên không nhớ nhiều về dự án và chúng tôi không thể phát triển một cuộc trò chuyện về những lựa chọn mà họ đưa ra và lý do đằng sau chúng. Tương tự, hãy đảm bảo rằng bạn trình bày công việc tốt nhất của mình và bạn đã dành đủ thời gian và nỗ lực cho nó. Tốt hơn nên có 2-3 dự án chất lượng cao hơn là 8–10 dự án chất lượng trung bình (hoặc thấp hơn).
Kết luận
Nếu bạn đang tìm kiếm vị trí lập trình viên data science, hãy dành chút thời gian và xem qua các điểm trong bài viết này. Sẽ không sao nếu bạn không thực hiện được một số mục trong bài viết này, nhưng bạn càng có thể làm được nhiều thì càng tốt. Hy vọng những mẹo nhỏ này sẽ giúp bạn nổi bật và ghi điểm được với nhà tuyển dụng. Bạn có cách tiếp cận khác khi sàng lọc CV cho vị trí lập trình viên chuyên ngành Khoa học Dữ Liệu không? Hãy chia sẻ trong phần bình luận bên dưới!
Xem thêm bài viết gốc tại đây !
Bạn có biết?
tham gia cộng đồng ITguru trên Linkedin, Facebook và các kênh mạng xã hội khác có thể giúp bạn nhanh chóng tìm được những chủ đề phát triển nghề nghiệp và cập nhật thông tin về việc làm IT mới nhất
Linkedin Page:
Facebook Group:
cơ hội việc làm IT : ITguru.vn






{kind=link}