Trí tuệ nhân tạo có sức lan tỏa mạnh mẽ và đang thay đổi mọi ngành công nghiệp. Dưới đây là những điều bạn cần biết về tiềm năng và hạn chế của học máy cũng như cách nó được sử dụng.
Machine learning (học máy) đứng sau các chatbots và các văn bản tiên đoán (predictive text), ứng dụng dịch ngôn ngữ, các bộ phim mà Netflix gợi ý cho bạn và cách trình bày các nguồn cấp dữ liệu truyền thông xã hội của bạn. Nó cung cấp năng lượng cho các phương tiện tự động và máy móc có thể chẩn đoán tình trạng y tế dựa trên hình ảnh.
Khi các công ty triển khai các chương trình trí tuệ nhân tạo, rất có thể họ đang sử dụng máy học – nhiều đến mức các thuật ngữ thường được sử dụng thay thế cho nhau và đôi khi không rõ ràng. Machine Learning là một lĩnh vực con của trí tuệ nhân tạo cung cấp cho máy tính khả năng học hỏi mà không cần được lập trình rõ ràng.
“Chỉ trong 5 hoặc 10 năm qua, học máy đã trở nên quan trọng, nếu không nói là quan trọng nhất, trong hầu hết các chương trình AI được thực hiện. Vì vậy, đó là lý do tại sao một số người sử dụng thuật ngữ AI và machine learning gần như đồng nghĩa với nhau… hầu hết những tiến bộ hiện tại trong AI đều liên quan đến học máy” giáo sư Thomas W. Malone, giám đốc sáng lập của MIT Center for Collective Intelligence tại MIT Sloan cho biết
Với sự phổ biến ngày càng tăng của machine learning, mọi người trong doanh nghiệp đều có thể gặp phải và sẽ cần một số kiến thức về lĩnh vực này. Một cuộc khảo sát của Deloitte năm 2020 cho thấy 67% công ty đang sử dụng máy học và 97% dự định hoặc có kế hoạch sử dụng nó trong năm tới.
Từ sản xuất đến bán lẻ, từ ngân hàng đến tiệm bánh, ngay cả các công ty đã có trước đây (legacy business) cũng đang sử dụng máy học để thêm giá trị hoặc tăng hiệu quả. Giáo sư khoa học máy tính Aleksander Madry của MIT cho biết: “Học máy đang thay đổi, hoặc sẽ thay đổi, mọi ngành và các nhà lãnh đạo cần hiểu các nguyên tắc cơ bản, cả tiềm năng và hạn chế”.
Mặc dù không phải ai cũng cần biết các chi tiết kỹ thuật, nhưng họ nên hiểu những gì công nghệ này làm được và những gì nó không thể làm, Madry nói thêm. “Tôi không nghĩ rằng không có ai mà không nhận thức được những gì đang xảy ra.”
Điều đó bao gồm nhận thức về các tác động xã hội, xã hội và đạo đức của học máy. “Điều quan trọng là phải tham gia và bắt đầu hiểu những công cụ này, sau đó suy nghĩ về cách bạn sẽ sử dụng chúng thành thạo. Chúng ta phải sử dụng những [công cụ] này vì lợi ích của mọi người, ”Tiến sĩ Joan LaRovere, MBA ’16, bác sĩ chăm sóc tích cực về tim cho nhi khoa và là người đồng sáng lập tổ chức phi lợi nhuận The Virtue Foundation cho biết. “AI có rất nhiều tiềm năng để làm điều tốt và chúng ta cần thực sự tập trung khi chúng ta suy nghĩ về điều này. Làm thế nào để sử dụng AI để làm điều tốt đẹp hơn cho thế giới? “
Học máy là gì?
Học máy là một lĩnh vực con của trí tuệ nhân tạo, được định nghĩa rộng rãi là khả năng của một cỗ máy bắt chước hành vi thông minh của con người. Hệ thống trí tuệ nhân tạo được sử dụng để thực hiện các nhiệm vụ phức tạp theo cách tương tự như cách con người giải quyết vấn đề.
Theo Boris Katz, principal research scientist và là người đứng đầu Nhóm InfoLab tại CSAIL, mục tiêu của AI là tạo ra các mô hình máy tính thể hiện “các hành vi thông minh” giống như con người. Điều này có nghĩa là máy có thể nhận dạng cảnh trực quan, hiểu văn bản được viết bằng ngôn ngữ tự nhiên hoặc thực hiện một hành động trong thế giới vật chất.
Máy học là một cách để sử dụng AI. Vào những năm 1950, nhà tiên phong về AI Arthur Samuel đã định nghĩa machine learning là “lĩnh vực nghiên cứu mang lại cho máy tính khả năng học hỏi mà không cần được lập trình rõ ràng”.
Định nghĩa đó đúng, theo Michael Shulman, giảng viên tại MIT Sloan và trưởng bộ phận máy học tại Kensho, chuyên về trí tuệ nhân tạo cho cộng đồng tài chính và trí tuệ Mỹ. Ông đã so sánh cách truyền thống của máy tính lập trình, hay “phần mềm 1.0”, với cách làm bánh, trong đó công thức yêu cầu lượng nguyên liệu chính xác và yêu cầu thợ làm bánh trộn trong một khoảng thời gian chính xác. Tương tự, lập trình truyền thống đòi hỏi phải tạo ra các hướng dẫn chi tiết để máy tính làm theo.
Nhưng trong một số trường hợp, việc viết chương trình để máy làm theo sẽ tốn nhiều thời gian hoặc không thể, chẳng hạn như huấn luyện máy tính nhận dạng ảnh của những người khác nhau. Mặc dù con người có thể thực hiện công việc này một cách dễ dàng, nhưng rất khó để nói cho máy tính biết cách thực hiện nó. Học máy có cách tiếp cận là để máy tính học cách tự lập trình thông qua trải nghiệm
Máy học bắt đầu với dữ liệu – số, ảnh hoặc văn bản, chẳng hạn như giao dịch ngân hàng, ảnh của mọi người hoặc thậm chí các mặt hàng bánh, hồ sơ sửa chữa, dữ liệu chuỗi thời gian từ cảm biến hoặc báo cáo bán hàng. Dữ liệu được thu thập và chuẩn bị để sử dụng làm dữ liệu đào tạo hoặc thông tin mà mô hình học máy sẽ được đào tạo. Càng nhiều dữ liệu, chương trình càng tốt.
Từ đó, các lập trình viên chọn một mô hình học máy để sử dụng, cung cấp dữ liệu và để mô hình máy tính tự đào tạo để tìm ra các mẫu hoặc đưa ra dự đoán. Theo thời gian, các lập trình viên có thể điều chỉnh mô hình, bao gồm cả việc thay đổi các tham số của nó, để giúp đưa nó đến kết quả chính xác hơn. (Trang web AI Weirdness của nhà khoa học Janelle Shane là một cái nhìn thú vị về cách các thuật toán học máy học và cách chúng có thể làm sai, như đã xảy ra khi một thuật toán cố gắng tạo ra các công thức và tạo ra Bánh Gà Sôcôla.)
Một số dữ liệu được lấy ra từ dữ liệu đào tạo (training data) để được sử dụng làm dữ liệu đánh giá, kiểm tra độ chính xác của mô hình học máy khi nó được hiển thị dữ liệu mới. Kết quả là một mô hình có thể được sử dụng trong tương lai với các bộ dữ liệu khác nhau.
Các thuật toán học máy thành công có thể làm những việc khác nhau, Malone đã viết trong một nghiên cứu tóm tắt gần đây về AI và tương lai của công việc cùng với các đồng tác giả, giáo sư MIT kiêm giám đốc CSAIL Daniela Rus và Robert Laubacher, phó giám đốc Trung tâm trí tuệ tập thể MIT .
“Chức năng của một hệ thống học máy có thể là mô tả (descriptive), nghĩa là hệ thống sử dụng dữ liệu để giải thích những gì đã xảy ra; tiên đoán (predictive), nghĩa là hệ thống sử dụng dữ liệu để dự đoán điều gì sẽ xảy ra; hoặc đề xuất (prescriptive), nghĩa là hệ thống sẽ sử dụng dữ liệu để đưa ra đề xuất về hành động cần thực hiện ”các nhà nghiên cứu viết.
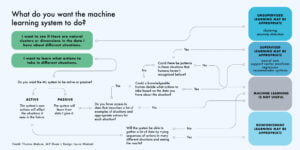
Ba danh mục phụ của học máy
- Các mô hình học máy có giám sát (Supervised machine learning) được đào tạo với các tập dữ liệu được gắn nhãn, cho phép các mô hình học và phát triển chính xác hơn theo thời gian. Ví dụ, một thuật toán sẽ được huấn luyện với hình ảnh của những con chó và những thứ khác, tất cả đều do con người dán nhãn và máy sẽ tự học cách nhận dạng hình ảnh của con chó. Máy học có giám sát là loại phổ biến nhất được sử dụng ngày nay.
- Trong học máy không giám sát (unsupervised machine learning), một chương trình tìm kiếm các mẫu trong dữ liệu không được gắn nhãn. Học máy không được giám sát có thể tìm thấy các mẫu hoặc xu hướng mà mọi người không tìm kiếm một cách rõ ràng. Ví dụ: một chương trình máy học không được giám sát có thể xem qua dữ liệu bán hàng trực tuyến và xác định các loại khách hàng khác nhau mua hàng.
- Học máy tăng cường (Reinforcement machine learning) huấn luyện máy thông qua thử và sai để thực hiện hành động tốt nhất bằng cách thiết lập hệ thống khen thưởng. Học tăng cường có thể huấn luyện các mô hình chơi trò chơi hoặc huấn luyện xe tự lái bằng cách cho máy biết khi nào máy đưa ra quyết định đúng, giúp máy học theo thời gian những hành động cần thực hiện.
Trong bản tóm tắt Công việc của tương lai, Malone lưu ý rằng học máy phù hợp nhất với các tình huống có nhiều dữ liệu – hàng nghìn hoặc hàng triệu ví dụ, như bản ghi âm từ các cuộc trò chuyện trước đó với khách hàng, nhật ký cảm biến từ máy hoặc các giao dịch ATM. Ví dụ: Google Dịch (Google Translate) có thể thực hiện chức năng dịch được vì nó đã “đào tạo” về lượng lớn thông tin trên web, bằng các ngôn ngữ khác nhau.
Trong một số trường hợp, học máy có thể đạt được cái nhìn sâu sắc hoặc tự động hóa việc ra quyết định trong những trường hợp mà con người không thể làm được, Madry nói. Ông nói: “Có thể không chỉ hiệu quả hơn và ít tốn kém hơn khi có một thuật toán làm điều này, mà đôi khi con người không thể làm được theo nghĩa đen.“
Tìm kiếm của Google là một ví dụ về điều gì đó mà con người có thể làm, nhưng không bao giờ ở quy mô và tốc độ mà các mô hình của Google có thể hiển thị câu trả lời tiềm năng mỗi khi một người nhập một truy vấn, Malone nói. “Đó không phải là một ví dụ về việc máy tính khiến mọi người không có việc làm. Đó là một ví dụ về việc máy tính thực hiện những việc mà sẽ không khả thi về mặt kinh tế nếu chúng phải do con người thực hiện ”.
Học máy liên kết với một số lĩnh vực trí tuệ nhân tạo khác
Xử lý ngôn ngữ tự nhiên
Xử lý ngôn ngữ tự nhiên (Natural language processing) là một lĩnh vực máy học, trong đó máy móc học cách hiểu ngôn ngữ tự nhiên như con người nói và viết, thay vì dữ liệu và số thường được sử dụng để lập trình máy tính. Điều này cho phép máy móc nhận dạng ngôn ngữ, hiểu và phản hồi lại ngôn ngữ cũng như tạo văn bản mới và dịch giữa các ngôn ngữ. Xử lý ngôn ngữ tự nhiên cho phép sử dụng công nghệ quen thuộc như chatbots và trợ lý kỹ thuật số như Siri hoặc Alexa.
Mạng nơron
Mạng nơ-ron (Neural networks ) là một lớp thuật toán học máy cụ thể được sử dụng phổ biến. Mạng nơ-ron nhân tạo được mô phỏng trên não người, trong đó hàng nghìn hoặc hàng triệu nút xử lý được kết nối với nhau và được tổ chức thành các lớp.
Trong mạng nơ-ron nhân tạo, các ô hoặc nút được kết nối với nhau, với mỗi đầu vào xử lý tế bào và tạo ra đầu ra được gửi đến các nơ-ron khác. Dữ liệu được gắn nhãn di chuyển qua các nút hoặc ô, với mỗi ô thực hiện một chức năng khác nhau. Trong một mạng nơ-ron được huấn luyện để xác định xem một bức ảnh có một con mèo hay không, các nút khác nhau sẽ đánh giá thông tin và đi đến một đầu ra cho biết một bức ảnh có con mèo hay không.
Học sâu
Mạng học sâu (Deep learning) là mạng nơ-ron có nhiều lớp. Mạng phân lớp có thể xử lý một lượng lớn dữ liệu và xác định “trọng lượng” của mỗi liên kết trong mạng. Ví dụ: trong hệ thống nhận dạng hình ảnh, một số lớp của mạng thần kinh có thể phát hiện các đặc điểm riêng lẻ của khuôn mặt, như mắt, mũi, hoặc miệng, trong khi một lớp khác có thể cho biết liệu những đặc điểm đó có xuất hiện theo cách chỉ ra một khuôn mặt hay không.
Giống như mạng lưới thần kinh, học sâu được mô phỏng theo cách bộ não con người hoạt động và cung cấp năng lượng cho nhiều hoạt động sử dụng máy học, như phương tiện tự hành, chatbot và chẩn đoán y tế.
“Bạn càng có nhiều lớp, bạn càng có nhiều tiềm năng để làm tốt những việc phức tạp” Malone nói.
Học sâu đòi hỏi tính toán rất nhiều, điều này làm dấy lên lo ngại về tính bền vững về kinh tế và môi trường của nó.
Cách các doanh nghiệp đang sử dụng máy học
Máy học là cốt lõi trong mô hình kinh doanh của một số công ty, như trong trường hợp thuật toán đề xuất của Netflix hoặc công cụ tìm kiếm của Google. Các công ty khác đang tham gia sâu vào học máy, mặc dù đó không phải là mảng kinh doanh chính của họ.
Nhiều người khác vẫn đang cố gắng xác định cách sử dụng máy học theo cách có lợi. “Theo tôi, một trong những vấn đề khó nhất trong học máy là tìm ra những vấn đề có thể giải quyết với học máy,” Shulman nói. “Vẫn còn một khoảng cách trong sự hiểu biết.”
Trong một bài báo năm 2018, các nhà nghiên cứu từ Sáng kiến MIT về Kinh tế Kỹ thuật số (MIT Initiative on the Digital Economy) đã đưa ra một phiếu đánh giá gồm 21 câu hỏi để xác định xem một nhiệm vụ có phù hợp với học máy hay không. Các nhà nghiên cứu phát hiện ra rằng không có nghề nghiệp nào không bị máy học ảnh hưởng, nhưng không có nghề nghiệp nào có khả năng bị nó tiếp quản hoàn toàn. Các nhà nghiên cứu đã tìm ra cách để có được thành công của học máy là tổ chức lại công việc thành các nhiệm vụ rời rạc, một số có thể được thực hiện bằng máy học và những công việc khác yêu cầu con người.
Một số cách các công ty đã sử dụng máy học
Các thuật toán khuyến nghị (Recommendation algorithms ): Các công cụ đề xuất (recommendation engines) đằng sau các đề xuất của Netflix và YouTube, thông tin nào xuất hiện trên nguồn cấp dữ liệu Facebook của bạn và các đề xuất sản phẩm được hỗ trợ bởi máy học. “[Các thuật toán] đang cố gắng tìm hiểu sở thích của chúng ta,” Madry nói. “Chúng muốn tìm hiểu, như trên Twitter, chúng ta muốn chúng hiển thị những dòng tweet nào. Hay trên Facebook, quảng cáo nào sẽ hiển thị, những bài đăng hoặc nội dung được thích (liked) nào được chia sẻ với chúng ta.”
Phân tích hình ảnh và phát hiện đối tượng (Image analysis and object detection): Máy học có thể phân tích hình ảnh cho các thông tin khác nhau, như học cách xác định mọi người và phân biệt họ, mặc dù các thuật toán nhận dạng khuôn mặt đang gây tranh cãi. Mục đích kinh doanh của việc này là khác nhau. Shulman lưu ý rằng các quỹ đầu cơ nổi tiếng sử dụng máy học để phân tích số lượng ô tô trong các bãi đậu xe, giúp họ tìm hiểu cách các công ty đang hoạt động và đánh cược vào đó.
Phát hiện gian lận (Fraud detection): Máy có thể phân tích các mẫu, như cách ai đó thường chi tiêu hoặc nơi họ thường mua sắm, để xác định các giao dịch thẻ tín dụng có khả năng gian lận, các nỗ lực đăng nhập hoặc email spam.
Đường dây trợ giúp tự động hoặc chatbot (Automatic helplines or chatbots ): Nhiều công ty đang triển khai chatbot trực tuyến, trong đó khách hàng hoặc đối tác không nói chuyện với con người mà thay vào đó là tương tác với máy. Các thuật toán này sử dụng máy học và xử lý ngôn ngữ tự nhiên, với các bot học từ bản ghi của các cuộc trò chuyện trước đây để đưa ra các phản hồi thích hợp.
Xe ô tô tự lái (Self-driving cars): Phần lớn công nghệ đằng sau ô tô tự lái dựa trên máy học, đặc biệt là học sâu.
Chẩn đoán và hình ảnh y tế (Medical imaging and diagnostics): Các chương trình máy học có thể được đào tạo để kiểm tra các hình ảnh y tế hoặc thông tin khác và tìm kiếm các dấu hiệu bệnh tật nhất định, giống như một công cụ có thể dự đoán nguy cơ ung thư dựa trên chụp quang tuyến vú.
Những hứa hẹn và thách thức của máy học
Mặc dù máy học đang thúc đẩy công nghệ có thể giúp người lao động hoặc mở ra những khả năng mới cho doanh nghiệp, nhưng có một số điều mà các nhà lãnh đạo doanh nghiệp nên biết về máy học và các giới hạn của nó.
Khả năng giải thích
Một lĩnh vực đáng quan tâm mà một số chuyên gia gọi là khả năng giải thích (explainability), hoặc khả năng làm rõ ràng về những gì các mô hình học máy đang làm và cách chúng đưa ra quyết định. Madry nói: “Hiểu tại sao một mô hình làm được và những gì nó làm thực sự là một câu hỏi rất khó, và bạn luôn phải tự hỏi mình như vậy. Bạn đừng bao giờ coi nó như một chiếc hộp đen, nó chỉ đến như một lời tiên tri… vâng, bạn nên sử dụng nó, nhưng sau đó hãy thử cảm nhận về những quy tắc ngón tay cái (rules of thumb) mà nó đưa ra? Và sau đó xác thực chúng ”.
Điều này đặc biệt quan trọng bởi vì các hệ thống có thể bị đánh lừa và phá hoại, hoặc thất bại trong một số nhiệm vụ mà con người có thể thực hiện dễ dàng. Ví dụ, việc điều chỉnh siêu dữ liệu trong hình ảnh có thể khiến máy tính nhầm lẫn – chỉ với một vài điều chỉnh, máy tính sẽ xác định được hình ảnh một con chó là một con đà điểu.
Madry chỉ ra một ví dụ khác trong đó thuật toán máy học kiểm tra tia X dường như hoạt động tốt hơn các bác sĩ. Nhưng hóa ra kết quả thuật toán có mối tương quan với các máy chụp ảnh, chứ không là ảnh được chụp ra. Bệnh lao phổ biến hơn ở các nước đang phát triển, những nước thường có máy móc cũ kỹ. Chương trình máy học đã học được rằng nếu chụp X-quang trên một máy cũ hơn, bệnh nhân có nhiều khả năng bị bệnh lao. Học máy đã hoàn thành nhiệm vụ, nhưng không theo cách mà các lập trình viên dự định hoặc sẽ thấy hữu ích.
Shulman cho biết tầm quan trọng của việc giải thích cách một mô hình hoạt động – và độ chính xác của nó – có thể khác nhau tùy thuộc vào cách nó được sử dụng. Mặc dù hầu hết các vấn đề được đặt ra đều có thể được giải quyết thông qua học máy, nhưng mọi người nên cho rằng ngay bây giờ các mô hình chỉ hoạt động với khoảng 95% độ chính xác của con người. Người lập trình và người xem có thể không có vấn đề nếu thuật toán đề xuất phim chính xác đến 95%, nhưng mức độ chính xác đó sẽ không đủ cho xe tự lái hoặc một chương trình được thiết kế để tìm ra những sai sót nghiêm trọng trong máy móc.
Thành kiến và kết quả không mong muốn
Máy móc được đào tạo bởi con người và thành kiến của con người có thể được đưa vào các thuật toán. Nếu thông tin thiên vị hoặc dữ liệu phản ánh sự bất bình đẳng được đưa vào chương trình máy học, chương trình sẽ học cách tái tạo nó và duy trì các hình thức phân biệt đối xử. Ví dụ, Chatbots được đào tạo về cách mọi người trò chuyện trên Twitter có thể sử dụng ngôn ngữ xúc phạm và phân biệt chủng tộc.
Trong một số trường hợp, mô hình học máy tạo ra hoặc làm trầm trọng thêm các vấn đề xã hội. Ví dụ: Facebook đã sử dụng máy học như một công cụ để hiển thị cho người dùng những quảng cáo và nội dung sẽ quan tâm và thu hút họ. Điều này đã dẫn đến các mô hình hiển thị cho mọi người nội dung cực đoan dẫn đến phân cực và lan truyền các thuyết âm mưu khi mọi người bị kích động, đảng phái , hoặc nội dung không chính xác.
Các cách để chống lại sự thiên vị trong học máy bao gồm xem xét cẩn thận dữ liệu đào tạo và hỗ trợ tổ chức đằng sau các nỗ lực trí tuệ nhân tạo có đạo đức, như đảm bảo tổ chức của bạn chấp nhận AI lấy con người làm trung tâm, tìm kiếm ý kiến đóng góp từ những người có nền tảng, kinh nghiệm và lối sống khác nhau khi thiết kế hệ thống AI. Các sáng kiến giải quyết vấn đề này bao gồm Liên minh Công lý Thuật toán (Algorithmic Justice League) và Dự án Cỗ máy Đạo đức (The Moral Machine).
Đưa machine learning vào hoạt động
Shulman cho biết các giám đốc điều hành thường gặp khó khăn với việc ứng dụng máy học để làm tăng giá trị cho công ty của họ. Những gì chỉ là phô trương của một công ty này có thể là cốt lõi đối của công ty khác và các doanh nghiệp nên tránh sa đà vào các xu hướng và tìm cách ứng dụng sao cho phù hợp với mục tiêu kinh doanh của mình.
Shulman đưa ra ví dụ, cách thức hoạt động của máy học đối với Amazon có lẽ sẽ không phù hợp cho một công ty ô tô. Amazon đã thành công với trợ lý giọng nói và loa vận hành bằng giọng nói, điều đó không có nghĩa là các công ty ô tô nên ưu tiên thêm loa vào ô tô. Công ty xe hơi có thể tìm ra cách sử dụng máy học trên dây chuyền nhà máy để tiết kiệm hoặc kiếm được nhiều tiền hơn.
Shulman nói: “Lĩnh vực này đang phát triển rất nhanh, và điều đó thật tuyệt vời, nhưng cũng khiến các nhà điều hành khó đưa ra quyết định về nó và quyết định lượng nguồn lực sẽ đổ vào đó.”
Shulman cho biết, tốt nhất bạn nên tránh xem máy học như một cách để tìm kiếm vấn đề. Một số công ty cố gắng ứng dụng học máy trong kinh doanh. Thay vì tập trung vào công nghệ, các doanh nghiệp nên tập trung vào một vấn đề kinh doanh hoặc nhu cầu của khách hàng có thể được đáp ứng bằng máy học.
LaRovere cho biết hiểu cơ bản về máy học là rất quan trọng, nhưng việc tìm ra cách sử dụng máy học phù hợp cuối cùng phụ thuộc vào những người có chuyên môn khác nhau làm việc cùng nhau. “Tôi không phải là nhà khoa học dữ liệu. Tôi không làm công việc kỹ thuật dữ liệu thực tế – như thu thập, xử lý và xử lý dữ liệu để kích hoạt các ứng dụng học máy – nhưng tôi hiểu rõ những điều đó để có thể làm việc với các nhóm để có được câu trả lời và có tác động chúng tôi cần. Bạn thực sự phải làm việc theo nhóm.”
Bài gốc của Sara Brown đăng trên mitsloan.mit.edu
Cover photo
Bạn có biết?
tham gia cộng đồng ITguru trên Linkedin, Facebook và các kênh mạng xã hội khác có thể giúp bạn nhanh chóng tìm được những chủ đề phát triển nghề nghiệp và cập nhật thông tin về việc làm IT mới nhất
Linkedin Page:
Facebook Group:
cơ hội việc làm IT : ITguru.vn






{kind=link}
Dễ hiểu, không quá nhiều thuật ngữ kỹ thuật