
Trong lĩnh vực khoa học dữ liệu (Data Science) co rất nhiều điều phải học và rất nhiều kiến thức cần theo đuổi. Tuy nhiên, có một số khái niệm cơ bản cốt lõi bạn cần phải nắm rõ. Bài này đưa ra hai mươi trong số những khái niệm đó để chuẩn bị cho một cuộc phỏng vấn xin việc về khoa học dữ liệu hoặc để làm mới lại kiến thức của bạn về Data Science.
1. Tập hợp dữ liệu – dataset
Đúng như tên gọi, khoa học dữ liệu là một nhánh của khoa học áp dụng phương pháp khoa học vào dữ liệu với mục tiêu nghiên cứu mối quan hệ giữa các đối tượng đặc trưng khác nhau và đưa ra kết luận có ý nghĩa dựa trên các mối quan hệ này. Do đó, dữ liệu là thành phần quan trọng trong khoa học dữ liệu. Tập dữ liệu là một ví dụ cụ thể của dữ liệu được sử dụng để phân tích hoặc xây dựng mô hình tại bất kỳ thời điểm nào. Tập dữ liệu có nhiều loại khác nhau như dữ liệu số, dữ liệu phân loại, dữ liệu văn bản, dữ liệu hình ảnh, dữ liệu thoại và dữ liệu video. Tập dữ liệu có thể là tĩnh (không thay đổi) hoặc động (thay đổi theo thời gian, ví dụ: giá cổ phiếu). Hơn nữa, một tập dữ liệu cũng có thể phụ thuộc vào không gian. Ví dụ, dữ liệu nhiệt độ ở Châu Á sẽ khác đáng kể với dữ liệu nhiệt độ ở Châu Âu. Đối với các dự án khoa học dữ liệu mới bắt đầu, loại tập dữ liệu phổ biến nhất là tập dữ liệu chứa dữ liệu số thường được lưu trữ ở định dạng tập giá trị được phân tách bằng dấu phẩy (CSV).
2. Sắp xếp dữ liệu – Data Wrangling
Sắp xếp dữ liệu (Data Wrangling) là quá trình chuyển đổi dữ liệu từ dạng thô sang dạng sẵn sàng để phân tích. Sắp xếp dữ liệu là một bước quan trọng trong tiền xử lý dữ liệu và bao gồm một số quy trình như nhập dữ liệu, làm sạch dữ liệu, cấu trúc dữ liệu, xử lý chuỗi, phân tích cú pháp HTML, xử lý ngày và giờ, xử lý dữ liệu bị thiếu và khai thác văn bản.
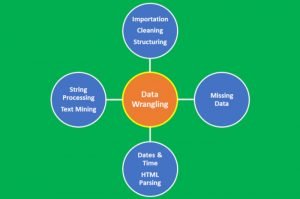
Quá trình sắp xếp dữ liệu là một bước quan trọng đối với bất kỳ nhà khoa học dữ liệu nào. Rất hiếm khi dữ liệu dễ dàng truy cập trong một dự án khoa học dữ liệu để phân tích. Nhiều khả năng dữ liệu nằm trong tập tin, trong cơ sở dữ liệu hoặc được trích xuất từ các tài liệu như trang web, mạng xã hội hoặc PDF. Biết cách sắp xếp và làm sạch dữ liệu sẽ cho phép bạn thu được thông tin chi tiết quan trọng từ dữ liệu của mình mà nếu không các dữ liệu đó sẽ bị ẩn.
3. Trực quan hóa dữ liệu – Data Visualization
Trực quan hóa dữ liệu là một trong những ngành quan trọng nhất của khoa học dữ liệu. Nó là một trong những công cụ chính được sử dụng để phân tích và nghiên cứu mối quan hệ giữa các biến khác nhau. Trực quan hóa dữ liệu, ví dụ: biểu đồ phân tán (scatter plots), biểu đồ đường (line grath), biểu đồ thanh (bar plots), biểu đồ (histograms) , biểu đồ qqp (qqplots), mật độ mịn (smooth densities), biểu đồ hình hộp (boxplots) , biểu đồ cặp (pair plots), bản đồ nhiệt (heat maps), v.v.) có thể được sử dụng cho phân tích mô tả. Trực quan hóa dữ liệu cũng được sử dụng trong học máy (machine learning) để tiền xử lý và phân tích dữ liệu, lựa chọn tính năng, xây dựng mô hình, kiểm tra mô hình và đánh giá mô hình. Khi chuẩn bị trực quan hóa dữ liệu, hãy nhớ rằng trực quan hóa dữ liệu là Nghệ thuật hơn là Khoa học. Để tạo ra hình ảnh tốt, bạn cần ghép nhiều đoạn mã lại với nhau để có kết quả cuối cùng tuyệt vời.
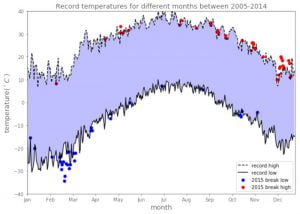
4. Bất thường (dị biệt) hay ngoại lai – Outliers
Ngoại lai là một điểm dữ liệu rất khác với phần còn lại của tập dữ liệu. Các giá trị ngoại lai thường chỉ là dữ liệu xấu. Lấy ví dụ: do cảm biến bị trục trặc, thí nghiệm bị ô nhiễm, hoặc lỗi của con người trong việc ghi dữ liệu. Đôi khi, các ngoại lai có thể chỉ ra một cái gì đó thực sự chẳng hạn như sự cố trong hệ thống. Các giá trị ngoại lai rất phổ biến và được mong đợi trong các bộ dữ liệu lớn. Một cách phổ biến để phát hiện các giá trị ngoại lai trong tập dữ liệu là sử dụng biểu đồ hộp. Hình bên dưới cho thấy một mô hình hồi quy đơn giản cho một tập dữ liệu chứa nhiều giá trị ngoại lai. Các giá trị ngoại lai có thể làm suy giảm đáng kể khả năng dự đoán của mô hình học máy. Một cách phổ biến để đối phó với các giá trị ngoại lai là đơn giản bỏ qua các điểm dữ liệu. Tuy nhiên, việc loại bỏ các giá trị ngoại lai của dữ liệu thực có thể quá lạc quan, dẫn đến các mô hình không thực tế. Các phương pháp nâng cao để đối phó với các ngoại lệ bao gồm phương pháp RANSAC.
5. Dữ liệu thay thế – Data Imputation
Hầu hết các tập dữ liệu đều chứa các giá trị bị thiếu. Cách dễ nhất để đối phó với dữ liệu bị thiếu chỉ đơn giản là vứt bỏ điểm dữ liệu bị thiếu đó. Tuy nhiên, việc loại bỏ các mẫu hoặc loại bỏ toàn bộ cột bị thiếu đó đơn giản là không khả thi vì bạn không thể để mất quá nhiều dữ liệu có giá trị. Trong trường hợp này, bạn có thể sử dụng các kỹ thuật nội suy khác nhau để ước tính các giá trị còn thiếu từ các mẫu đào tạo khác trong tập dữ liệu đang có. Một trong những kỹ thuật nội suy phổ biến nhất là mean imputation, trong đó bạn chỉ cần thay thế giá trị bị thiếu bằng giá trị trung bình của toàn bộ cột thiếu thông tin. Cách khác để thay thế các giá trị bị thiếu là lấy trung bình hoặc nhập các giá trị thường xuyên nhất. Bất kể phương pháp nào bạn sử dụng trong mô hình của mình bạn cũng phải nhớ rằng áp đặt chỉ là một phép gần đúng và do đó có thể tạo ra lỗi trong mô hình cuối cùng. Nếu dữ liệu được cung cấp đã từng được xử lý trước đó, bạn sẽ cần phải tìm hiểu xem các giá trị bị thiếu được xem xét như thế nào. Tỉ lệ phần trăm dữ liệu ban đầu đã bị loại bỏ là bao nhiêu? Phương pháp nào đã được sử dụng để ước tính các giá trị bị thiếu?
6. Co giãn dữ liệu – Data Scaling
Việc mở rộng các thuộc tính (feature) sẽ giúp cải thiện chất lượng và khả năng dự đoán của mô hình đang có. Ví dụ: giả sử bạn muốn xây dựng một mô hình để dự đoán mức độ tín nhiệm của biến mục tiêu dựa trên các biến dự đoán như thu nhập và điểm tín dụng. Vì điểm tín dụng nằm trong khoảng từ 0 đến 850 trong khi thu nhập hàng năm có thể từ 25.000 đến 500.000 đô la, nếu không mở rộng các thuộc tính , mô hình sẽ thiên về tính năng thu nhập. Điều này có nghĩa là hệ số trọng số liên quan đến tham số thu nhập sẽ rất nhỏ, điều này sẽ khiến mô hình dự báo chỉ dự đoán mức độ tín nhiệm dựa trên tham số thu nhập.
Để đưa các thuộc tính (features) lên cùng một quy mô, ta có thể quyết định sử dụng bình thường hóa (normalization) hoặc chuẩn hóa (standardization) các thuộc tính. Thông thường, chúng ta giả định dữ liệu được phân phối bình thường và mặc định theo hướng tiêu chuẩn hóa, nhưng điều đó không phải luôn luôn như vậy. Điều quan trọng là trước khi quyết định sử dụng bình thường hóa hay chuẩn hóa, trước tiên bạn hãy xem cách các thuộc tính được phân phối thế nào. Nếu các thuộc tính có xu hướng được phân phối đồng nhất, thì ta có thể sử dụng normalization (MinMaxScaler). Nếu các thuộc tính xấp xỉ Gaussian, thì chúng ta có thể sử dụng standardization (StandardScaler). Lưu ý rằng cho dù bạn sử dụng phương pháp normalization hay normalization, thì đây cũng là những phương pháp gần đúng và có liên quan đến sai số tổng thể của mô hình.
Bạn có thể tìm hiểu sự khác nhau giữa normalization và standardization ở đây
7. Phân tích thành phần chính – Principal Component Analysis (PCA)
Các dataset lớn với hàng trăm hoặc hàng nghìn thuộc tính thường dẫn đến dư thừa, đặc biệt là khi các thuộc tính tương quan với nhau. Việc đào tạo một mô hình trên tập dữ liệu nhiều chiều (high-dimensional dataset ) có quá nhiều thuộc tính đôi khi có thể dẫn đến trang bị quá mức (overfitting, tức mô hình thu được cả hiệu ứng thực và ngẫu nhiên). Ngoài ra, một mô hình quá phức tạp có quá nhiều đặc trưng có thể khó diễn giải. Một cách để giải quyết vấn đề dư thừa là thông qua các kỹ thuật lựa chọn tính năng và giảm kích thước như Phân tính thành phần chính (Principal Component Analysis – PCA). Phân tích thành phần chính (PCA) là một phương pháp thống kê được sử dụng để trích xuất các thuộc tính. PCA được sử dụng cho dữ liệu nhiều chiều và tương quan. Ý tưởng cơ bản của PCA là chuyển đổi không gian ban đầu của các thuộc tính (feature) thành không gian của thành phần chính. Chuyển đổi PCA đạt được những điều sau: a) Giảm số lượng các thuộc tính được sử dụng trong mô hình cuối cùng bằng cách chỉ tập trung vào các thành phần chiếm phần lớn phương sai trong tập dữ liệu. b) Loại bỏ mối tương quan giữa các features.
8.Phân tích phân biệt tuyến tính – Linear Discriminant Analysis (LDA)
PCA và LDA là hai kỹ thuật chuyển đổi tuyến tính tiền xử lý dữ liệu thường được sử dụng để giảm kích thước để chọn các thuộc tính liên quan có thể được sử dụng trong thuật toán học máy. PCA là một thuật toán không giám sát (unsupervised algorithm) được sử dụng để trích xuất các thuộc tính trong dữ liệu tương quan và nhiều chiều. PCA đạt được việc giảm kích thước bằng cách chuyển đổi các thuộc tính thành các trục thành phần trực giao với phương sai tối đa trong tập dữ liệu. Mục tiêu của LDA là tìm ra không gian con của thuộc tối ưu hóa khả năng phân tách lớp và giảm kích thước. Do đó, LDA là một thuật toán được giám sát.
Việc triển khai LDA có thể được tìm thấy tại liên kết này: LDA Sử dụng Bộ dữ liệu Iris
9.Phân chia dữ liệu – Data Partitioning
Trong học máy, tập dữ liệu thường được phân chia thành các tập huấn luyện (training) và thử nghiệm. Mô hình được huấn luyện trên tập dữ liệu huấn luyện và sau đó được thử nghiệm trên tập dữ liệu thử nghiệm. Do đó, tập dữ liệu thử nghiệm hoạt động như một tập dữ liệu không nhìn thấy được, có thể được sử dụng để ước tính lỗi tổng quát hóa (generalization error – lỗi dự kiến khi mô hình được áp dụng cho tập dữ liệu trong thế giới thực sau khi mô hình đã được triển khai). Trong scikit-learn (thư viện mã nguồn mở dành cho học máy) có thể sử dụng công cụ ước tính phân tách thử nghiệm / đào tạo để phân chia tập dữ liệu như sau:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
Trong đó X là ma trận thuộc tính (feature matrix) và y là biến mục tiêu (target variable). Trong trường hợp này, tập dữ liệu thử nghiệm được là 30%.
10- Học có giám sát – Supervised Learning
Đây là các giải thuật học máy thực hiện việc học bằng cách nghiên cứu mối quan hệ giữa các biến đặc trưng và biến mục tiêu đã biết. Học tập có giám sát (Supervised Learning ) có hai danh mục phụ:
Continuous Target Variables – Các biến mục tiêu liên tục
Các thuật toán để dự đoán các biến mục tiêu liên tục bao gồm Hồi quy tuyến tính (Linear Regression), hồi quy KNeighbors (KNeighbors regression- KNR) và Hồi quy vectơ hỗ trợ (Support Vector Regression – SVR).
Hướng dẫn về hồi quy tuyến tính và KNeighbors được tìm thấy tại đây: Hướng dẫn về hồi quy tuyến tính và KNeighbors
Discrete Target Variables – Biến mục tiêu rời rạc
Các thuật toán để dự đoán các biến mục tiêu rời rạc bao gồm:
- Perceptron classifier
- Logistic Regression classifier
- Support Vector Machines (SVM)
- Decision tree classifier
- K-nearest classifier
- Naive Bayes classifier
11. Học không giám sát – Unsupervised Learning
Trong học không giám sát (Unsupervised Learning) chúng ta xử lý dữ liệu không được gắn nhãn hoặc dữ liệu có cấu trúc không xác định. Sử dụng các kỹ thuật học không giám sát, ta có thể khám phá cấu trúc dữ liệu của mình để trích xuất thông tin có ý nghĩa mà không cần sự hướng dẫn của biến kết quả đã biết hoặc hàm phần thưởng (reward function). K-mean clustering là một ví dụ về thuật toán học không giám sát.
12. Học tăng cường – Reinforcement Learning
Trong học tăng cường, mục tiêu là phát triển một hệ thống (agent) cải thiện hiệu suất của nó dựa trên các tương tác với môi trường (environment). Vì thông tin về trạng thái hiện tại của môi trường thường cũng bao gồm tín hiệu khen thưởng (reward signal), chúng ta có thể coi học tăng cường như một lĩnh vực liên quan đến học có giám sát. Tuy nhiên, trong học tăng cường, phản hồi này không phải là nhãn hoặc giá trị sự thật cơ bản chính xác mà là thước đo mức độ hành động được đo lường bằng hàm phần thưởng. Thông qua tương tác với môi trường, một tác nhân sau đó có thể sử dụng học tăng cường để học một loạt các hành động nhằm tối đa hóa phần thưởng này.
13. Model Parameters và Hyperparameters
Trong một mô hình máy học (Machine learning model), có hai loại tham số (parameter):
- Model Parameter (tham số mô hình): Đây là các tham số trong mô hình phải được xác định bằng cách sử dụng tập dữ liệu huấn luyện (training data set). Đây là các thông số được trang bị (fitted parameters). Giả sử chúng ta có một mô hình chẳng hạn như giá nhà = a + b * (tuổi) + c * (kích thước), để ước tính chi phí của ngôi nhà dựa trên tuổi của ngôi nhà và kích thước của nó thì a, b, và c sẽ là mô hình hoặc các thông số được trang bị.
- Hyperparameters (siêu tham số) : Đây là những thông số có thể điều chỉnh phải được điều chỉnh để có được một mô hình với hiệu suất tối ưu.Ví dụ về siêu tham số được hiển thị ở đây:
KNeighborsClassifier(n_neighbors = 5, p = 2, metric = ‘minkowski’)
Điều quan trọng là trong quá trình đào tạo, các siêu thông số phải được điều chỉnh để có được mô hình có hiệu suất tốt nhất (với các thông số được trang bị tốt nhất -best-fitted parameters).
Hướng dẫn về tham số mô hình và siêu tham số được tìm thấy tại đây
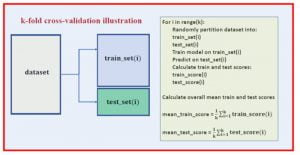
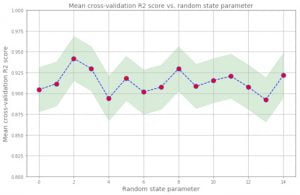
14. Kiểm chứng hay xác thực chéo – Cross-validation
Kiểm chứng chéo là một phương pháp đánh giá hiệu suất của mô hình học máy trên các mẫu ngẫu nhiên của tập dữ liệu. Điều này đảm bảo rằng mọi thành kiến trong tập dữ liệu đều được ghi lại. Xác thực chéo có thể giúp chúng ta có được các ước tính đáng tin cậy về lỗi tổng quát hóa của mô hình, nghĩa là mô hình hoạt động tốt như thế nào trên dữ liệu không nhìn thấy (unseen data). Trong xác nhận chéo k lần (k-fold cross-validation), tập dữ liệu được phân chia ngẫu nhiên thành các tập huấn luyện và thử nghiệm. Mô hình được huấn luyện trên tập huấn luyện và được đánh giá trên tập thử nghiệm. Quá trình được lặp lại k-lần. Sau đó, điểm đào tạo và kiểm tra trung bình được tính bằng cách lấy trung bình trên k-lần. Đây là mã giả xác thực chéo k-lần:
15. Cân bằng định kiến-phương sai – Bias-variance Tradeoff
Trong thống kê và học máy, sự cân bằng định kiến-phương sai (Bias-variance Tradeoff) là thuộc tính của một tập hợp các mô hình dự đoán, theo đó các mô hình có độ chệch thấp hơn trong ước lượng tham số có phương sai cao hơn của ước tính tham số giữa các mẫu và ngược lại. Vấn đề hay sự tiến thoái lưỡng nan của bias-variance là xung đột trong việc cố gắng giảm thiểu đồng thời hai nguồn lỗi này sẽ ngăn các thuật toán học có giám sát tổng quát hóa ngoài tập huấn luyện của chúng:
- Sự thiên vị (bias) là một lỗi do các giả định sai lầm trong thuật toán học tập.
Độ chệch cao hay high bias (quá đơn giản – overly simple ) có thể khiến thuật toán bỏ sót các mối quan hệ liên quan giữa các tính năng và đầu ra mục tiêu (trang bị thiếu).
- Phương sai (variance) là một sai số từ độ nhạy đối với các dao động nhỏ trong tập huấn luyện.
Phương sai cao (quá phức tạp – overly complex) có thể gây ra một thuật toán mô hình nhiễu ngẫu nhiên trong dữ liệu huấn luyện hơn là kết quả đầu ra dự định (overfitting).
Điều quan trọng là phải tìm ra sự cân bằng phù hợp giữa tính đơn giản và phức tạp của mô hình. Hướng dẫn về cân bằng phương sai lệch có thể được tìm thấy tại đây: Hướng dẫn về cân bằng phương sai lệch
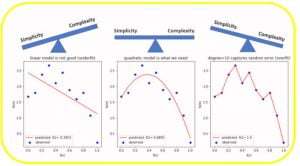
16. Chỉ số đánh giá – Evaluation Metrics
Trong học máy (phân tích dự đoán- predictive analytics), có một số số liệu có thể được sử dụng để đánh giá mô hình. Ví dụ: mô hình học có giám sát (mục tiêu liên tục) có thể được đánh giá bằng cách sử dụng các số liệu như điểm số R2, sai số bình phương trung bình (mean square error– MSE) hoặc sai số tuyệt đối trung bình (mean absolute error– MAE). Hơn nữa, mô hình học tập có giám sát (mục tiêu rời rạc – discrete target), còn được gọi là mô hình phân loại, có thể được đánh giá bằng cách sử dụng các số liệu như độ chính xác, độ chính xác, thu hồi, điểm f1 và diện tích dưới đường cong ROC (AUC).
17. Định lượng không chắc chắn – Uncertainty Quantification
Định lượng không chắc chắn (Uncertainty Quantification – UQ) có thể được định nghĩa là quá trình định lượng độ không đảm bảo kết hợp với các tính toán mô hình về các đại lượng thực, vật lý cần quan tâm (QOI), với mục tiêu tính toán tất cả các nguồn có liên quan của độ không đảm bảo và định lượng sự đóng góp của các nguồn cụ thể vào độ không đảm bảo tổng thể.
Điều quan trọng là phải xây dựng các mô hình học máy mang lại các ước tính không thiên vị về sự không chắc chắn trong các kết quả được tính toán. Do tính ngẫu nhiên vốn có trong tập dữ liệu và mô hình, các tham số đánh giá như điểm số R2 là các biến ngẫu nhiên, và do đó điều quan trọng là phải ước tính mức độ không chắc chắn trong mô hình.
18. Các khái niệm toán học – Math Concepts
Giải tích cơ bản (Basic Calculus): Hầu hết các mô hình học máy được xây dựng với tập dữ liệu có một số tính năng hoặc công cụ dự đoán. Do đó, việc làm quen với phép tính nhiều biến là cực kỳ quan trọng để xây dựng mô hình học máy.
- Đây là những chủ đề bạn cần làm quen: Hàm của một số biến; Derivatives & gradients; hàm bước, chức năng Sigmoid, hàm Logit, hàm ReLU (Rectified Linear Unit); hàm ước lượng; hàm vẽ; Giá trị nhỏ nhất và lớn nhất của một hàm
Đại số tuyến tính cơ bản (Basic Linear Algebra): Đại số tuyến tính là kỹ năng toán học quan trọng nhất trong học máy. Tập dữ liệu được biểu diễn dưới dạng ma trận. Đại số tuyến tính được sử dụng trong tiền xử lý dữ liệu, biến đổi dữ liệu, giảm kích thước và đánh giá mô hình.
- Đây là những chủ đề bạn cần làm quen: Vectơ; Định mức của một vectơ; Ma trận; Chuyển vị của một ma trận; Nghịch đảo của ma trận; Định thức của một ma trận; Dấu vết của một ma trận; Dot product; Eigenvalues; Eigenvectors
Phương pháp tối ưu hóa (Optimization Methods): Hầu hết các thuật toán học máy thực hiện mô hình dự đoán bằng cách tối thiểu hóa một hàm mục tiêu, do đó tìm hiểu các trọng số phải được áp dụng cho dữ liệu thử nghiệm để có được các nhãn dự đoán.
- Đây là những chủ đề bạn cần làm quen: Hàm chi phí / Hàm mục tiêu; Hàm khả năng xảy ra; Chức năng lỗi; Thuật toán Gradient Descent và các biến thể của nó (ví dụ: Stochastic Gradient Descent Algorithm)
Bạn có thể xem thêm chi tiết về toán học cho Machine Learning, Deep Learning trong bài viết trước của ITguru
19. Các khái niệm về xác suất thống kê – Statistics and Probability Concepts
Thống kê và Xác suất được sử dụng để trực quan hóa các tính năng, xử lý trước dữ liệu, chuyển đổi tính năng, truyền dữ liệu, giảm kích thước, kỹ thuật tính năng, đánh giá mô hình, v.v. Dưới đây là các chủ đề bạn cần làm quen:
- Mean, Median, Mode, Standard deviation/variance, Correlation coefficient and the covariance matrix (Hệ số tương quan và ma trận hiệp phương sai), Probability distributions (Binomial, Poisson, Normal), p-value, Bayes Theorem (Precision, Recall, Positive Predictive Value, Negative Predictive Value, Confusion Matrix, ROC Curve), Central Limit Theorem, R_2 score, Mean Square Error (MSE), A/B Testing, Monte Carlo Simulation.
20. Công cụ năng suất – Productivity Tools
Một dự án phân tích dữ liệu điển hình có thể bao gồm một số phần, mỗi phần bao gồm một số tập dữ liệu và các tập lệnh khác nhau với code. Giữ tất cả những điều này có tổ chức có thể là một thách thức Các công cụ năng suất (Productivity Tools ) giúp bạn giữ các dự án có tổ chức và duy trì hồ sơ về các dự án đã hoàn thành. Một số công cụ năng suất cần thiết như Unix / Linux, git và GitHub, RStudio và Jupyter Notebook.
Tham khảo bài viết gốc trên kdnuggets.com
Bạn có biết?
tham gia cộng đồng ITguru trên Linkedin, Facebook và các kênh mạng xã hội khác có thể giúp bạn nhanh chóng tìm được những chủ đề phát triển nghề nghiệp và cập nhật thông tin về việc làm IT mới nhất
Linkedin Page:
Facebook Group:
cơ hội việc làm IT : ITguru.vn






{kind=link}