Học sâu (Deep Learning) và mạng thần kinh thực sự phức tạp. Vì vậy, trong buổi phỏng vấn tìm việc Data Science (Khoa Học Dữ Liệu), có rất nhiều khái niệm liên quan đến Deep Learning mà người phỏng vấn sẽ hỏi bạn. Dưới đây là 10 khái niệm học sâu thường gặp trong các buổi phỏng vấn đồng thời giải thích tại sao chúng lại quan trọng như vậy.
1. Hàm kích hoạt – Activation Functions
Nếu bạn chưa hiểu cơ bản về mạng nơ-ron và cấu trúc của nó thì nên tìm hiểu trước khi tìm hiểu về hàm kích hoạt (activation fuction).
Khi bạn đã hiểu về mạng thần kinh và nodes, một hàm kích hoạt như một công tắc đèn, nó xác định một nơ-ron cần kích hoạt hay không.
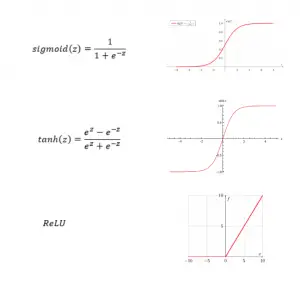
Có một số hàm kích hoạt nhưng phổ biến nhất là hàm Rectified Linear Unit, hay còn gọi ngắn gọn là hàm ReLU. Hàm ReLU tốt hơn hàm sigmoid và ham tand vì nó hội tụ nhanh hơn. Chú ý trong một ảnh khi x (hay z) lớn, độ dốc rất nhỏ sẽ làm chậm độ hội tụ một cách rất rõ. Tuy nhiên, điều này không đúng với hàm ReLu.
2. Hàm chi phí – Cost Function
Hàm chi phí (Cost function) dùng trong mạng thần kinh cũng tương tự như bất kỳ hàm chi phí nào bạn dùng trog các mô hình học máy (machine learning). Nó dùng để đo xem mức độ “tốt” của một mạng thần kinh liên quan đến giá trị mà nó dự đoán so với giá trị thật. Hay nói cách khác, hàm chi phí dùng để tính độ chính xác của thuật toán ta áp dụng. Hàm chi phí tỷ lệ nghịch với chất lượng của mô hình – mô hình càng tốt thì hàm chi phí càng thấp và ngược lại.
Mục đích của hàm chi phí là để bạn có giá trị cần tối ưu hóa. Bằng cách giảm thiểu hàm chi phí của mạng thần kinh, bạn sẽ đạt được trọng số và thông số tối ưu của mô hình, do đó tối đa hóa hiệu suất của mô hình.
Có một số cost function thường được sử dụng, bao gồm chi phí bậc hai, chi phí entropy chéo, chi phí hàm mũ, khoảng cách Hellinger, phân kỳ Kullback-Leibler, v.v.
3. Truyền ngược – Backpropagation
Backpropagation là một thuật toán có quan hệ chặt chẽ với hàm chi phí. Cụ thể, nó là một thuật toán được sử dụng để tính toán gradient của hàm chi phí. Nó đã được rất nhiều người ưa chuộng và sử dụng do tốc độ và hiệu quả so với các cách tiếp cận khác.
Tên của nó bắt nguồn từ thực tế là việc tính toán gradient bắt đầu với gradient của lớp cuối cùng và đi ngược lại gradient của lớp đầu tiên. Do đó, sai số ở lớp k phụ thuộc vào lớp k + 1 tiếp theo.
4. Mạng nơ-ron tích chập – Convolutional Neural Networks
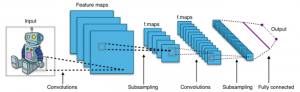
Mạng thần kinh tích chập (Convolutional Neural Network -CNN) là một loại mạng thần kinh nhận đầu vào (thường là hình ảnh), gán tầm quan trọng cho các tính năng khác nhau của hình ảnh và đưa ra dự đoán. Điều làm cho CNN tốt hơn mạng nơ-ron truyền thẳng (feedforward neural networks) là nó nắm bắt tốt hơn sự phụ thuộc không gian (pixel) xuyên suốt hình ảnh, có nghĩa là nó có thể hiểu thành phần của hình ảnh tốt hơn.
Bạn có thể quan tâm, CNNs sử dụng một phép toán được gọi là tích chập. Wikipedia định nghĩa tích chập là một phép toán trên hai hàm tạo ra một hàm thứ ba biểu thị cách hình dạng của một hàm được sửa đổi bởi hàm kia. Do đó, CNN sử dụng tích chập thay vì phép nhân ma trận chung trong ít nhất một trong các lớp của chúng.
5. Mạng thần kinh hồi quy – Recurrent Neural Networks
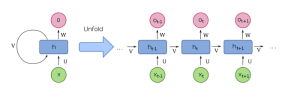
Mạng nơ-ron hồi quy (Recurrent Neural Network – RNNs) là một loại mạng nơ-ron khác hoạt động đặc biệt tốt với dữ liệu tuần tự do khả năng nhập các đầu vào có kích thước khác nhau. RNN xem xét cả đầu vào hiện tại cũng như đầu vào trước đó mà nó đã được đưa ra, có nghĩa là cùng một đầu vào về mặt kỹ thuật có thể tạo ra một đầu ra khác dựa trên các đầu vào trước đó đã cho.
Về mặt kỹ thuật, RNN là một loại mạng thần kinh nơi các kết nối giữa các nút tạo thành một đồ thị dọc theo trình tự thời gian, cho phép chúng sử dụng bộ nhớ trong để xử lý các chuỗi đầu vào có độ dài thay đổi.
6. Mạng bộ nhớ dài – ngắn – Long Short-Term Memory Networks
Mạng Bộ nhớ dài ngắn (Long Short-Term Memory – LSTM) là một loại Mạng thần kinh hồi quy (RNN) nhằm giải quyết một trong những thiếu sót của RNN: RNN có short-term memory.
Cụ thể, nếu một sequence quá dài, tức là nếu có độ trễ lớn hơn 5–10 bước, RNN có xu hướng loại bỏ thông tin đã được cung cấp trong các bước trước đó. Ví dụ: nếu bạn đưa một paragraph vào RNN, nó có thể bỏ qua thông tin được cung cấp ở đầu của paragraph.
7. Khởi tạo trọng số – Weight Initialization
Điểm chính của khởi tạo trọng số (weight initialization) là đảm bảo mạng nơ-ron không đồng quy thành một nghiệm tầm thường (trivial solution).
Nếu tất cả các trọng số đều được khởi tạo với cùng một giá trị (ví dụ bằng 0) thì mỗi đơn vị sẽ nhận được chính xác cùng một tín hiệu và mọi layer sẽ hoạt động như thể nó là một ô duy nhất.
Do đó, bạn muốn khởi tạo ngẫu nhiên các trọng số gần bằng không, nhưng không bằng không. Đây là kỳ vọng của thuật toán tối ưu hóa ngẫu nhiên được sử dụng để đào tạo mô hình.
8. Batch vs. Stochastic Gradient Descent
Batch gradient descent và stochastic gradient descent là hai phương pháp khác nhau để tính gradient.
Batch gradient descent chỉ đơn giản là tính toán gradient bằng cách sử dụng toàn bộ tập dữ liệu. Nó chậm hơn nhiều, đặc biệt là với các bộ dữ liệu lớn hơn nhưng tốt hơn cho tập lồi (convex) hoặc trơn.
Với stochastic gradient descent, độ dốc (gradient) được tính toán bằng cách sử dụng một mẫu đào tạo duy nhất tại một thời điểm. Do đó, tính toán nhanh hơn và ít tốn kém hơn. Do đó, tuy nhiên, khi đạt đến mức tối ưu toàn cục, nó có xu hướng bị bật lại – điều này dẫn đến một giải pháp tốt nhưng không phải là một giải pháp tối ưu.
9. Siêu tham số – Hyperparameters
Siêu tham số (Hyperparameter) là các biến quy định cấu trúc mạng và các biến chi phối cách mà mạng được huấn luyện. Các siêu tham số phổ biến bao gồm:
- Các thông số kiến trúc mô hình như số lớp, số đơn vị ẩn, v.v.
- Tốc độ học (The learning rate)
- Network weight initialization
- Số lượng epoch (được định nghĩa là một chu kỳ thông qua toàn bộ tập dữ liệu đào tạo)
- Batch size
- …
10. Tốc độ học – Learning Rate
Tốc độ học tập (learning rate) là một siêu tham số được sử dụng trong mạng thần kinh kiểm soát mức độ điều chỉnh mô hình để đáp ứng với lỗi ước tính mỗi khi trọng số mô hình được cập nhật.
Nếu tỷ lệ học tập quá thấp, mô hình của bạn sẽ đào tạo rất chậm vì các bản cập nhật tối thiểu được thực hiện đối với trọng số qua mỗi lần lặp. Do đó, sẽ mất nhiều bản cập nhật trước khi đạt đến điểm tối thiểu.
Nếu learning rate được đặt quá cao sẽ gây ra hành vi khác biệt không mong muốn đối với hàm mất mát (loss function) do cập nhật về trọng số và nó có thể không hội tụ.
Kết luận
Trên đây là 10 khái niệm quan trọng bạn cần phải nắm trước khi bước vào cuộc phỏng vấn tìm việc Data Science. Tuy nhiên sẽ là không đủ nếu chỉ biết những khái niệm đó và phỏng vấn có thành công hay không còn tùy thuộc vào kiến thức, kinh nghiệm và khả năng mà bạn có được. Và cũng lưu ý, thông tin trong bài chỉ để tham khảo và bạn cần tìm hiểu sâu và chi tiết hơn với những link tham khảo có sẵn hoặc từ những nguồn tài liệu mà bạn có
Tham khảo bài gốc tại đây
Bạn có biết?
tham gia cộng đồng ITguru trên Linkedin, Facebook và các kênh mạng xã hội khác có thể giúp bạn nhanh chóng tìm được những chủ đề phát triển nghề nghiệp và cập nhật thông tin về việc làm IT mới nhất
Linkedin Page:
Facebook Group:
cơ hội việc làm IT : ITguru.vn






{kind=link}